Baseline System
Overview
The baseline system for CHiME-9 Task 2 aims to address the problem of Enhancing Conversations for the Hearing Impaired (ECHI) in noisy cafeteria-style environments. The system uses the noisy audio (recorded through either hearing aid-style devices or Meta Aria glasses) and a speaker enrollment sample, which is an audio recording of each participant reading the first paragraph of the Rainbow Passage.
Task Requirements
The provided baseline is used to extract the speech of the conversation partners from the noisy mixture. The input to the system is the multi-channel noisy recording from the hearing aids/Aria glasses and a single-channel recording of the rainbow passage. The output of this system is single-channel audio of the target participant’s speech. To obtain the speech of all three conversation partners, the system is run three times, once with each participant’s rainbow passage.
System Architecture
The baseline system can be found on the GitHub repo. It it is based on the TF-GridNet architecture [1,2], with modifications based on [3,4] to make it more suitable for this task.
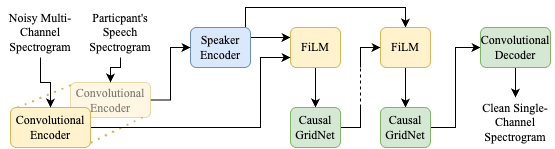
The main adaptations from the base TF-GridNet model [1,2] are:
- Expanding the encoder to accept multiple channels of audio
- The speaker encoder as implemented in [4]
- Feature-wise Linear Modulation (FiLM) to infuse the speaker information into the audio representation, as described in [3]
- Modifications to the GridNet blocks to make it a causal system, as described in [3]
Stages
- The convolutional encoder processes both the noisy device audio and the participant’s speech passage (in separate passes).
- The output obtained from the participant’s speech is then processed by a speaker encoder, which produces a speaker embedding.
- FiLM infuses the speaker embedding into the noisy audio representation.
- A causal GridNet block processes the infused representation.
- Steps 3 and 4 can be repeated.
- A convolutional decoder produces the spectrogram of the clean speech.
Results
Key objective metrics for the baseline system are given below. For all metrics, higher scores are better. The metrics are computed on the speech segments for each speaker in the development set.
The individual scores are computed using only the audio produced for the target speaker, whereas the summed scores are computed using the sum of the audio produced for each speaker in the session (see rules).
The ‘Passthrough’ system is the score achieved doing no enhancement. Specifically, for the Aria, it simply returns the nose-bridge microphone signals as the estimate for all three participants; for the HA device, it returns the sum of the front mic of the left and right ear device.
| Individual | Device | Frequency-Weighted Segmental SNR | STOI | PESQ | Csig | Cbak | Covl |
|---|---|---|---|---|---|---|---|
| Passthrough | Aria | 1.06 | 0.47 | 1.11 | 1.55 | 1.35 | 1.23 |
| Baseline | Aria | 2.34 | 0.50 | 1.16 | 1.56 | 1.24 | 1.26 |
| Passthrough | HA | 0.89 | 0.46 | 1.11 | 1.57 | 1.13 | 1.23 |
| Baseline | HA | 2.27 | 0.46 | 1.11 | 1.53 | 1.25 | 1.21 |
| Summed | Device | Frequency-Weighted Segmental SNR | STOI | PESQ | Csig | Cbak | Covl |
|---|---|---|---|---|---|---|---|
| Passthrough | Aria | 1.40 | 0.51 | 1.14 | 1.74 | 1.32 | 1.34 |
| Baseline | Aria | 3.29 | 0.57 | 1.23 | 1.89 | 1.20 | 1.46 |
| Passthrough | HA | 1.18 | 0.48 | 1.12 | 1.70 | 1.10 | 1.30 |
| Baseline | HA | 3.26 | 0.51 | 1.15 | 1.87 | 1.20 | 1.40 |
For instructions on how to compute your own metrics, please refer to the GitHub Documentation.
Example distributions
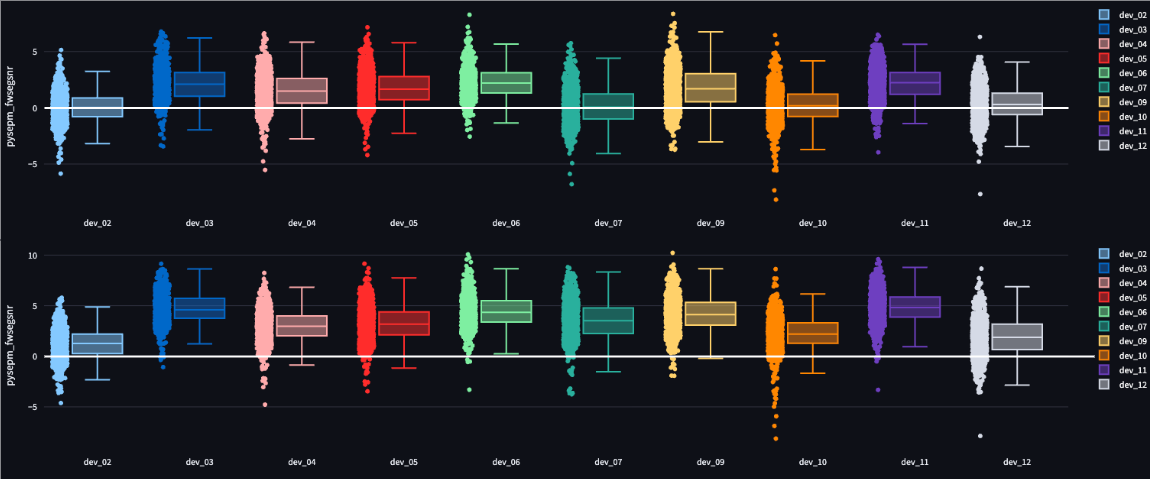
The figures below show the distribution of metric scores for the segments across the dev set recording sessions.
- Frequency-Weighted Segmental SNR (FWSegSNR) for Summed segments
Hearing Aid – Passthrough (top) and Baseline (bottom)
Aria – Passthrough (top) and Baseline (bottom)
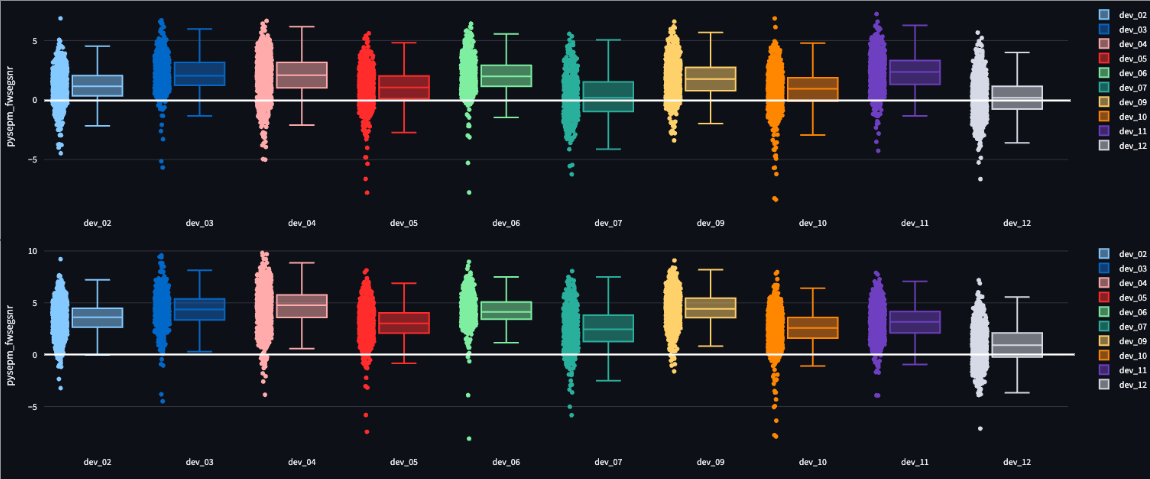
The images above have been produced with the ECHI MetricViewer tool.
References
[1] Z.-Q. Wang, S. Cornell, S. Choi, Y. Lee, B.-Y. Kim, and S. Watanabe, “TF-GridNet: Integrating Full- and Sub-Band Modelling for Speech Separation”, in TASLP, 2023.
[2] Z.-Q. Wang, S. Cornell, S. Choi, Y. Lee, B.-Y. Kim, and S. Watanabe, “TF-GridNet: Making Time-Frequency Domain Models Great Again for Monaural Speaker Separation”, in ICASSP, 2023.
[3] Cornell, S., Wang, Z. Q., Masuyama, Y., Watanabe, S., Pariente, M., & Ono, N. (2023). Multi-channel target speaker extraction with refinement: The wavlab submission to the second clarity enhancement challenge.
[4] Fengyuan Hao, Xiaodong Li, Chengshi Zheng, “X-TF-GridNet: A time–frequency domain target speaker extraction network with adaptive speaker embedding fusion”, in Information Fusion, 2024.