CHiME-9 Task 1 - MCoRec
Multi-Modal Context-aware Recognition
CHiME-9 Task 1 targets the problem of Multi-Modal Context-aware Recognition (MCoRec) in a single-room environment. The goal is to process a single 360° video and audio recording of a room where multiple, separate conversations are happening simultaneously, and to both transcribe each speaker’s speech and identify which speakers belong to the same conversation. This task addresses the challenging scenario of understanding overlapping conversations in natural social environments, where multiple groups of people engage in distinct discussions within the same physical space.
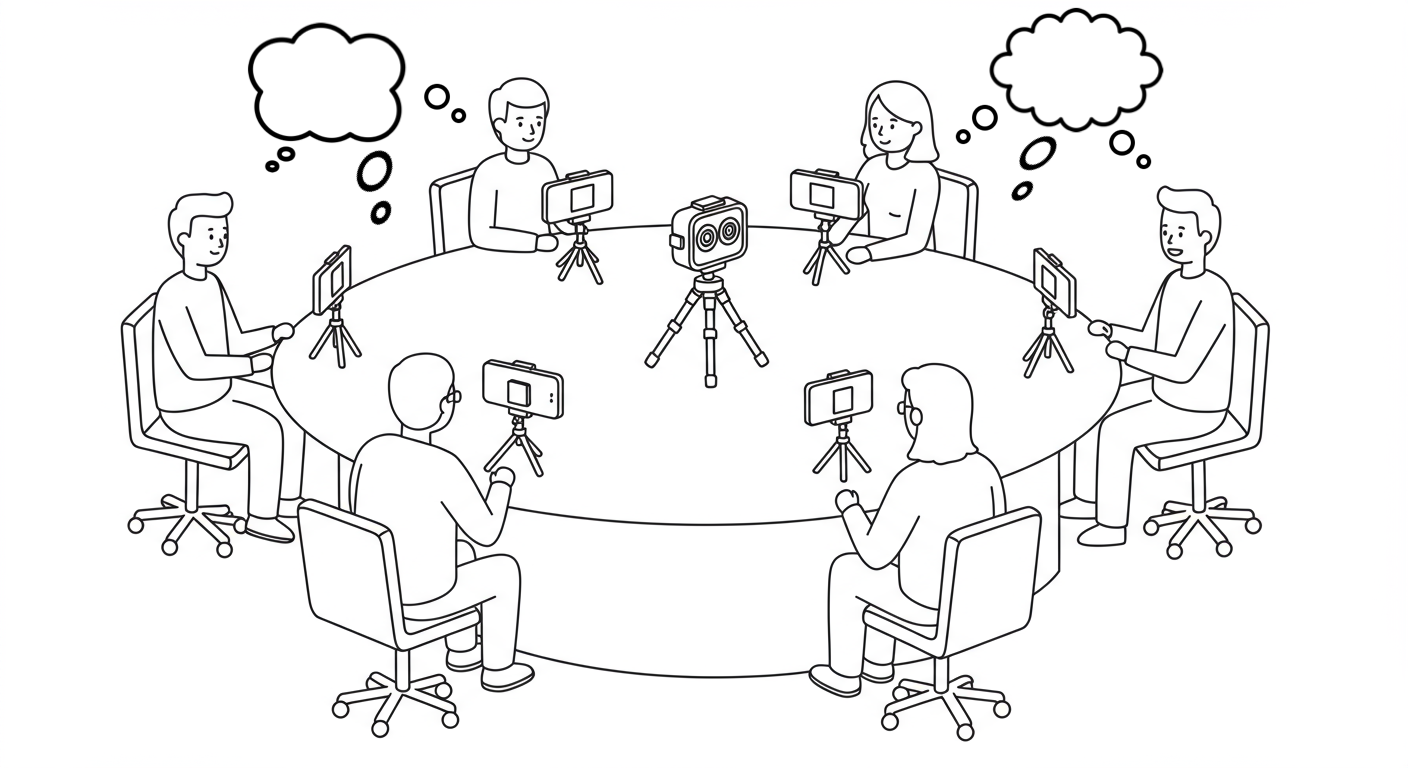
Key Challenge Features
- Multiple concurrent conversations occurring simultaneously in the same room
- Single 360° camera and microphone capturing all participants from a central viewpoint
- High speech overlap ratios reaching up to 100% due to simultaneous conversations
- Real, unscripted conversations covering everyday topics like hobbies, work, entertainment, and personal stories
- Natural acoustic environments with realistic background noise from other ongoing conversations
- Up to 8 active speakers divided into up to 4 simultaneous conversations
- Combined transcription and clustering challenge requiring both accurate speech recognition and conversation grouping
Quick start
- Datasets: MCoRec data
- Baseline model: MCoRec baseline
The Scenario
The MCoRec dataset captures natural conversational scenarios where 2-8 participants are seated around a table and divided into groups of 2-4 speakers each. Participants engage in unscripted conversations on topics including everyday life, work, school, hypotheticals, entertainment, news, and personal stories. Sessions typically last around 6 minutes, during which multiple separate conversations occur simultaneously, creating a challenging acoustic environment with significant speech overlap. A moderator signals the start and end of each session with a distinctive whistle to facilitate synchronization.
The Recording Setup
- 360° Camera: GoPro Max positioned at the center of the table, capturing 4K resolution video at 25fps with single-channel audio at 16kHz
- Individual Smartphones: Each speaker has a smartphone placed in front of them (selfie mode) recording at 720p resolution
- Lapel Microphones: Close-talking microphones connected to smartphones via adapters, positioned near each speaker’s mouth for enhanced audio clarity
- Seating Arrangement: All speakers sit around a table with varying distances depending on table size
- Session Synchronization: Moderator whistle cues enable precise alignment of recordings from multiple devices
- Recording Duration: Each session typically lasts approximately 6 minutes.
Note: Individual smartphone recordings and lapel microphone audio are only available for the training set to facilitate system development. The development and evaluation sets contain only the central 360° video and audio, as the core challenge focuses on processing the difficult multi-speaker, multi-conversation scenario captured by the central camera setup with high speech overlap and acoustic complexity.
Task Description
The challenge consists of a single comprehensive track requiring participants’ systems to:
- Individual Speaker Transcription: Generate time-aligned transcripts (
.vttfiles) for each target speaker, accurately capturing their speech content within the specified evaluation time intervals. - Conversation Clustering: Group participants into their respective conversations by generating a speaker-to-cluster mapping.
Input: Single 360° video and its corresponding audio track, along with bounding boxes to identify the list of target participants.
Output: Per-speaker transcriptions and conversation cluster assignments
Evaluation and Ranking
The evaluation uses three complementary metrics:
- Individual Speaker’s WER: Word Error Rate computed for each speaker’s transcription
- Conversation Clustering Performance: Pairwise F1 score measuring clustering accuracy
- Joint ASR-Clustering Error Rate (Primary Metric): Combined metric that weights transcription performance and clustering performance
Important Dates
- Data Release: July 1st, 2025 (train and dev sets)
- Evaluation Data Release: 28 Jan 2026
- Final Submission Deadline: 6 Feb 2026
- Workshop: 4 May 2026
Organizers
- Alexander Waibel (CMU, USA & KIT, DE)
- Christian Fuegen (Meta, UK)
- Shinji Watanabe (CMU, USA)
- Katerina Zmolikova (Meta, UK)
- Thai-Binh Nguyen (KIT, DE)
- Pingchuan Ma (Meta, USA)
For any questions about the challenge, please contact us:
- Email: mcorecchallenge@gmail.com
- Slack: CHiME Challenge Community