Results
![]()
We would like to thank all participants of the NOTSOFAR-1 challenge for their efforts and congratulate them for contributing to science and advancing the field of meeting transcription. We look forward to seeing your continued contributions and we hope the datasets, code and research resulting from this challenge will benefit the entire speech community.
Single-Channel Track
Results and Official Ranking
Below we report the speaker-attributed tcpWER as well as the speaker-agnostic tcORC WER metrics (lower is better) on the evaluation and development (dev-set-2) subsets.
The metrics are first computed for each session (see code) and then averaged.
Teams are ranked based on the best-performing system (out of up to 4 submissions allowed) on the evaluation set using tcpWER, and only these systems are reported.
See submission and rules for more information.
| Rank | Team Name | System Tag | tcpWER (%) (eval) | tcpWER (%) (dev) | tcorcWER (%) (eval) | tcorcWER (%) (dev) |
|---|
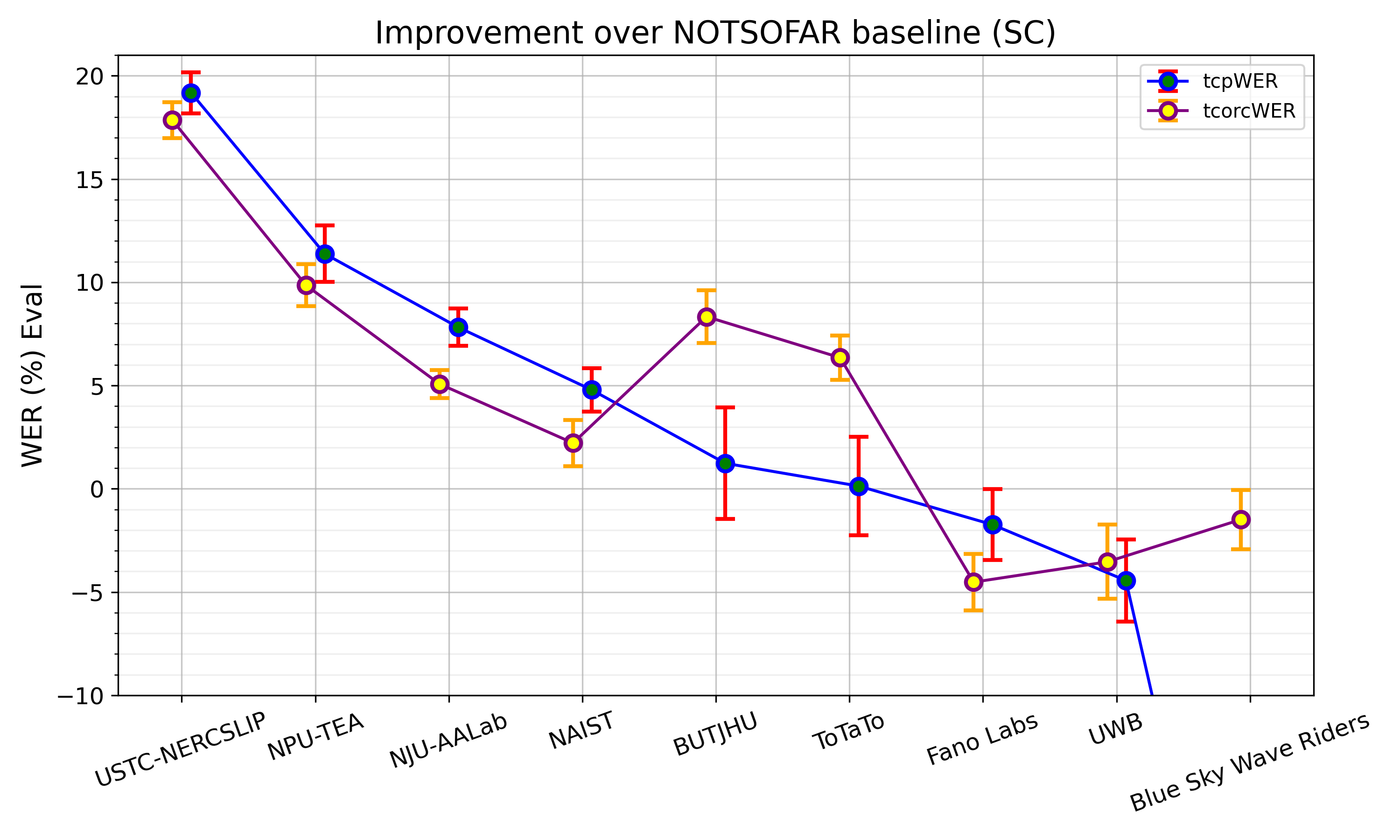
Confidence Intervals - Improvement Over Baseline
The plot below shows each team’s absolute improvement relative to the NOTSOFAR baseline (larger is better) along with confidence intervals, for both tcpWER and tcorcWER.
The confidence intervals are estimated using a paired test based on Student’s t-distribution applied to the differences baseline.wer - system.wer. Meetings are treated as approximately independent and identically distributed (i.i.d.) samples. Specifically, to calculate a meeting’s tcpWER, we average the tcpWER values of its constituent sessions (e.g. plaza_0 and rockfall_2 devices), and then treat these averages as i.i.d samples.
See code for details and further documentation.
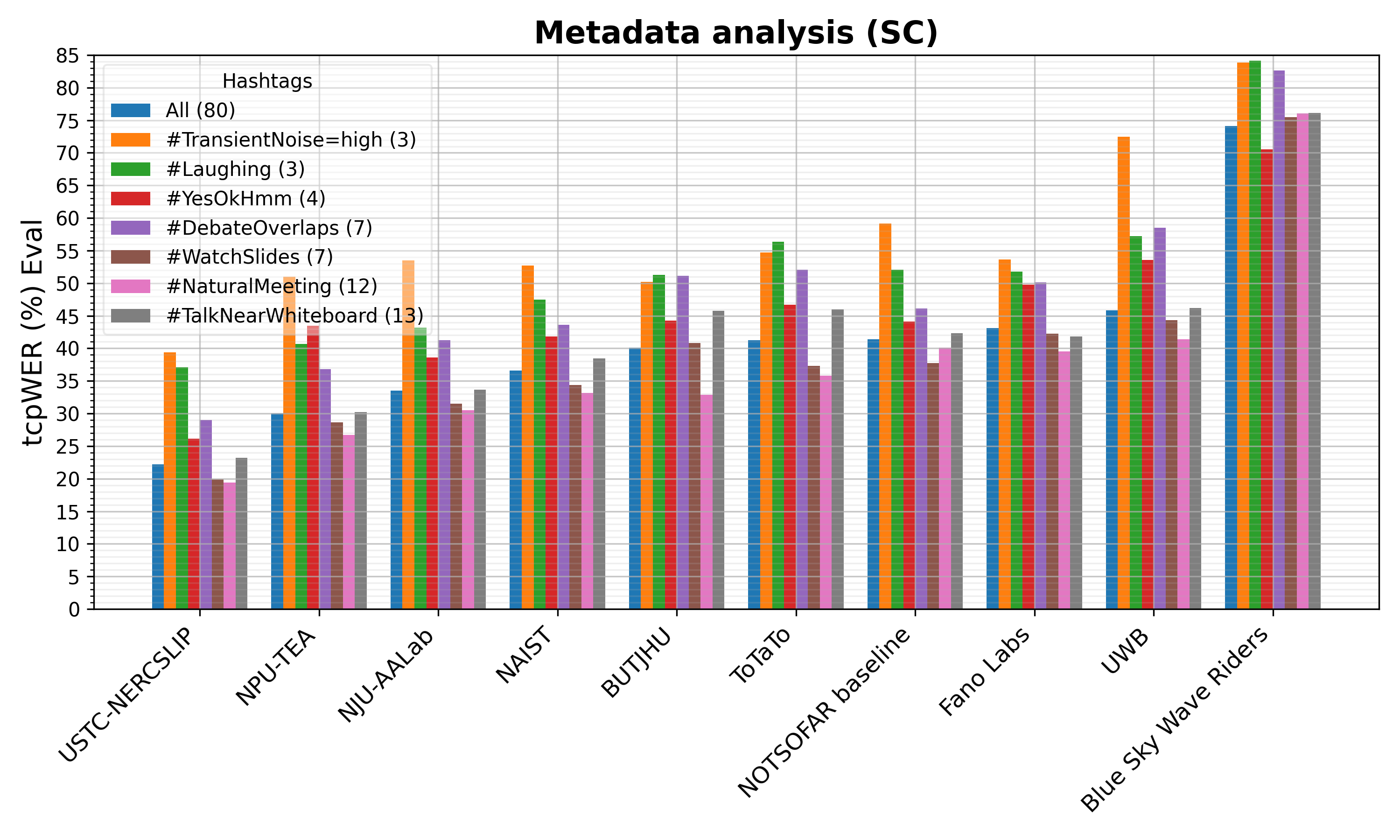
Metadata Analysis
The NOTSOFAR meetings are labeled by their acoustic scenarios using hashtags (refer to the Metadata section for details). To provide a more detailed performance analysis of the systems, we compute the tcpWER conditioned on selected hashtags. The figure’s legend below is formatted as hashtag (number of meetings). Only hashtags associated with three or more meetings are included.
Multi-Channel Track
Results and Official Ranking
Below we report the speaker-attributed tcpWER as well as the speaker-agnostic tcORC WER metrics (lower is better) on the evaluation and development (dev-set-2) subsets.
The metrics are first computed for each session (see code) and then averaged.
Teams are ranked based on the best-performing system (out of up to 4 submissions allowed) on the evaluation set using tcpWER, and only these systems are reported.
See submission and rules for more information.
DASR and NOTSOFAR: Both tasks focus on distant automatic speech recognition and speaker diarization, offering a fundamental comparison among different system designs when evaluated on NOTSOFAR: geometry-agnostic (DASR) versus known geometry (NOTSOFAR). Since none of the NOTSOFAR teams participating in the multi-channel track used the core training datasets for the DASR task (CHiME-6, DiPCo, Mixer6), we have decided to include only NOTSOFAR entries in the official ranking below for a fair comparison.
However, all subsequent sections also include DASR entries, marked as “(DASR)”, to provide scientific insights.
| Rank | Team Name | System Tag | tcpWER (%) (eval) | tcpWER (%) (dev) | tcorcWER (%) (eval) | tcorcWER (%) (dev) |
|---|
NOTSOFAR and DASR Results (supplementary)
Extending on the official ranking we also report both NOTSOFAR and DASR multi-channel results, including baselines.
| Rank | Team Name | System Tag | tcpWER (%) (eval) | tcpWER (%) (dev) | tcorcWER (%) (eval) | tcorcWER (%) (dev) |
|---|
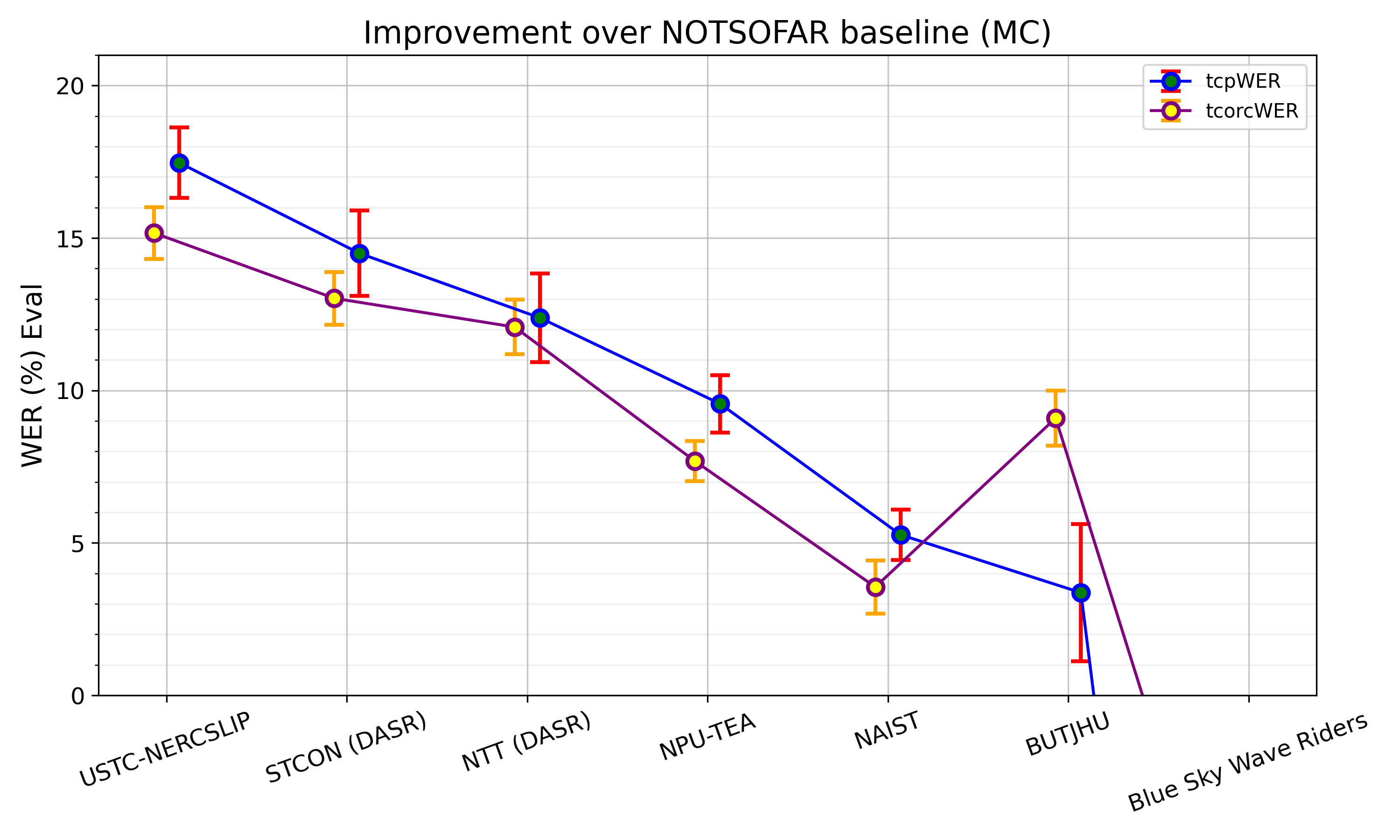
Confidence Intervals - Improvement Over Baseline
The plot below shows each team’s absolute improvement relative to the NOTSOFAR baseline (larger is better) along with confidence intervals, for both tcpWER and tcorcWER.
The confidence intervals are estimated using a paired test based on Student’s t-distribution applied to the differences baseline.wer - system.wer. Meetings are treated as approximately independent and identically distributed (i.i.d.) samples. Specifically, to calculate a meeting’s tcpWER, we average the tcpWER values of its constituent sessions (e.g. plaza_0 and rockfall_2 devices), and then treat these averages as i.i.d samples.
See code for details and further documentation.
Please note that for enhanced interpretability, some results that significantly underperformed the baseline are excluded.
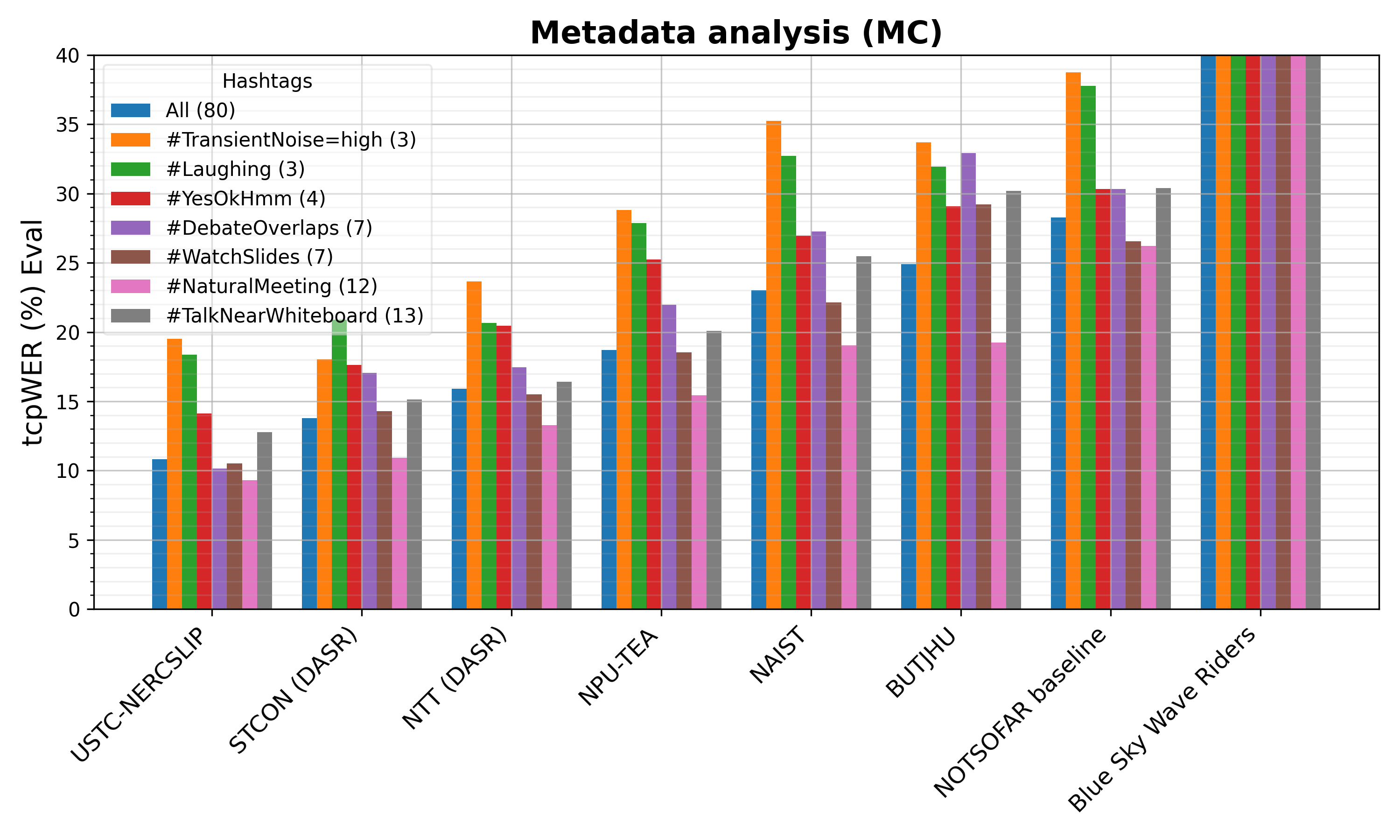
Metadata Analysis
The NOTSOFAR meetings are labeled by their acoustic scenarios using hashtags (refer to the Metadata section for details). To provide a more detailed performance analysis of the systems, we compute the tcpWER conditioned on selected hashtags. The figure’s legend below is formatted as hashtag (number of meetings). Only hashtags associated with three or more meetings are included.
Supplementary Results - All Tracks and Systems, NOTSOFAR and DASR
The following provides more detailed results with all systems submitted to both NOTSOFAR and DASR, including baselines.
| Rank | Team Name | Track | System Tag | tcpWER (%) (eval) | tcpWER (%) (dev) | tcorcWER (%) (eval) | tcorcWER (%) (dev) |
|---|