Data
The main CHiME-9 ECHI dataset consists of recordings of conversations between four participants seated around a table. During the sessions, a cafeteria environment is simulated using a set of 18 loudspeakers positioned in the recording room. In each session, one participant is using Aria glasses (Project Aria) and another is wearing hearing aid devices with two microphones per ear. The task is to enhance the audio arriving at the device microphones to improve it for the purposes of conversation.
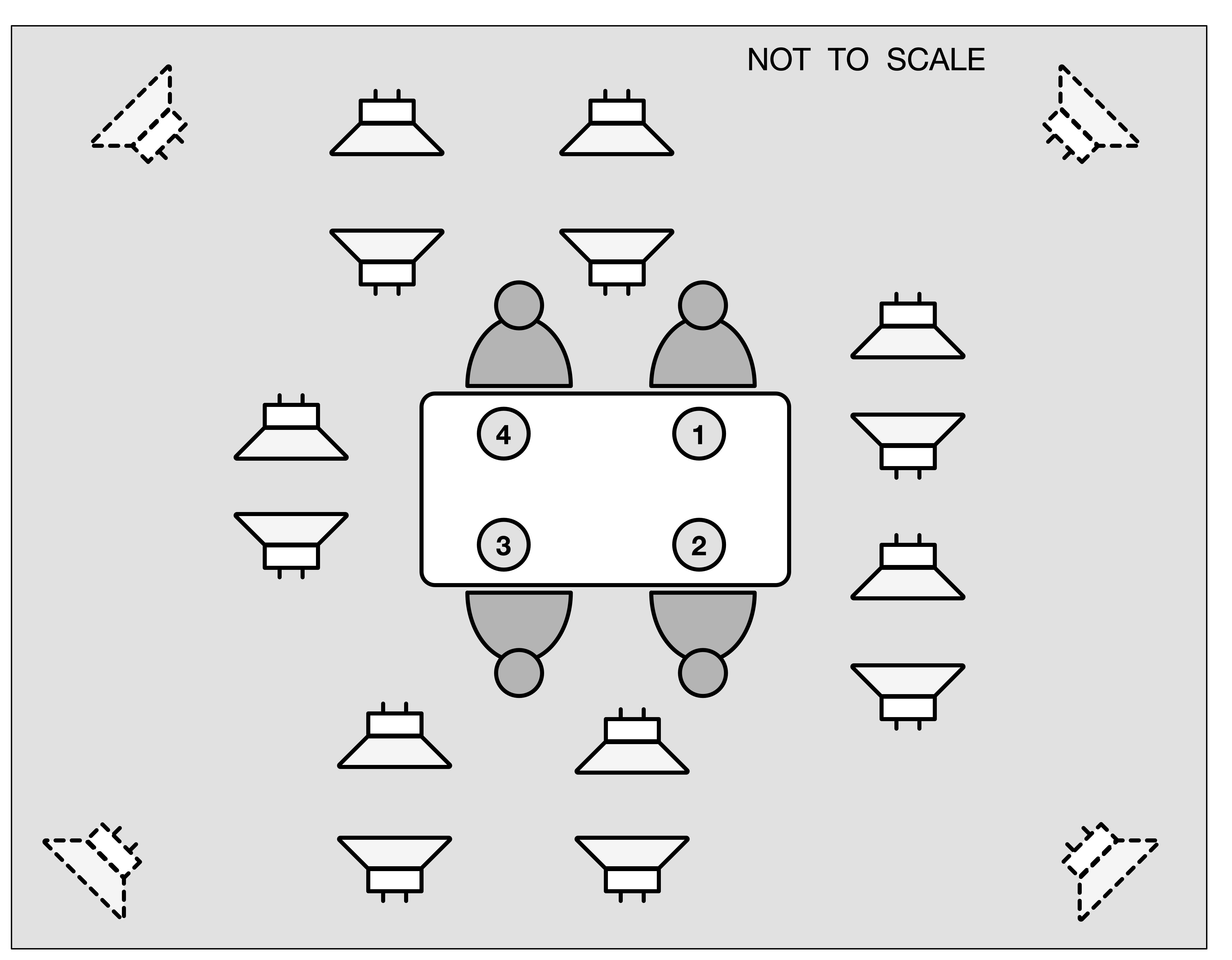
The figure below shows a photo of the recording room showing four participants engaged in the task (left), and a schematic illustrating how the loudspeakers are used (right).
 |  |
Additional details:
- 14 of the loudspeakers were used to simulate up to 7 simultaneous two-person conversations, using data from either the LibriSpeech dataset or the spontaneous speech samples from the EARS dataset.
- Additional sound events from FSD50K were sparsely mixed into the 14 conversation channels. These were selected using the semantic tags to pick categories considered appropriate for a cafeteria environment, such as clinking glasses and coughs.
- Ambient sound was added using four additional loudspeakers placed facing the room corners and playing background audio from the WHAM! dataset.
- All recordings were made in the same room, but variability was introduced by making small movements to the position and direction of the 14 conversational loudspeakers, and by changing the configuration of the room’s absorber panels between sessions.
For instructions for obtaining the data, jump to Getting the data.
Description of the ECHI dataset
The data has been provided from 49 separate recording sessions, each of 36 minutes duration. These have been split into training, development and evaluation subsets. Each dataset is fully disjoint with respect to the conversation participants, the LibriSpeech/EARS speakers, the ambient noise environments and the sound effect materials that are used to create the interfering sound during the sessions. The evaluation subset will remain hidden until shortly before the final submission deadline. A baseline system is provided that has been trained on the training subset and evaluated on the development subset. Participants can use the training subset to build their system and the development subset to compare against the baseline. No training or automatic fine-tuning is allowed on the development set.
| split | background | # sessions | # speakers | duration |
|---|---|---|---|---|
| train | LibriSpeech | 30 | 118 | 18.0 h |
| dev | LibriSpeech | 4 | 16 | 2.4 h |
| EARS | 6 | 24 | 3.6 h | |
| eval | LibriSpeech | 5 | 20 | 3.0 h |
| EARS | 4 | 16 | 2.4 h |
The development and evaluation subsets each contain sessions using both LibriSpeech and EARS spontaneous speech as background sources. These are treated as unified sets: evaluation scores will be averaged across all sessions within each subset, irrespective of background type.
For each session, the following are provided
- audio recorded by the Aria glasses (7 channels)
- audio recorded by the Hearing Aids (4 channels)
- close talk audio (1 channel per participant)
- head position and orientation (per participant), 250 Hz frame-rate
- participant speech (clean, read speech recordings for target speaker extraction)
- a set of reference signals to use for evaluation or as a training objective, together with a segmentation file that identifies the start and end time of the speech segments in the reference that will be evaluated.
All audio is recorded at 48 kHz.
Note in the figure above that the locations at the table are numbered 1, 2, 3 and 4. These position numbers are used in the metadata, e.g., to identify the location of the person wearing the Aria glasses and the hearing aid, and to associate close talk microphone and head tracking data with participants.
Detailed description of data structure and formats
The directory structure is as follows (note that the evaluation subdirectories will be distributed shortly before the submission deadline):
├── aria
│ ├── train
│ ├── dev
│ └── eval
├── ha
│ ├── train
│ ├── dev
│ └── eval
├── ct
│ ├── train
│ ├── dev
│ └── eval
├── ref
│ ├── train
│ ├── dev
│ └── eval
├── tracker
│ ├── train
│ ├── dev
│ └── eval
├── participant
│ ├── train
│ ├── dev
│ └── eval
└─── metadata
├── train/ref
├── dev/ref
└── eval/ref
Formats of the data in the subdirectories are as follows:
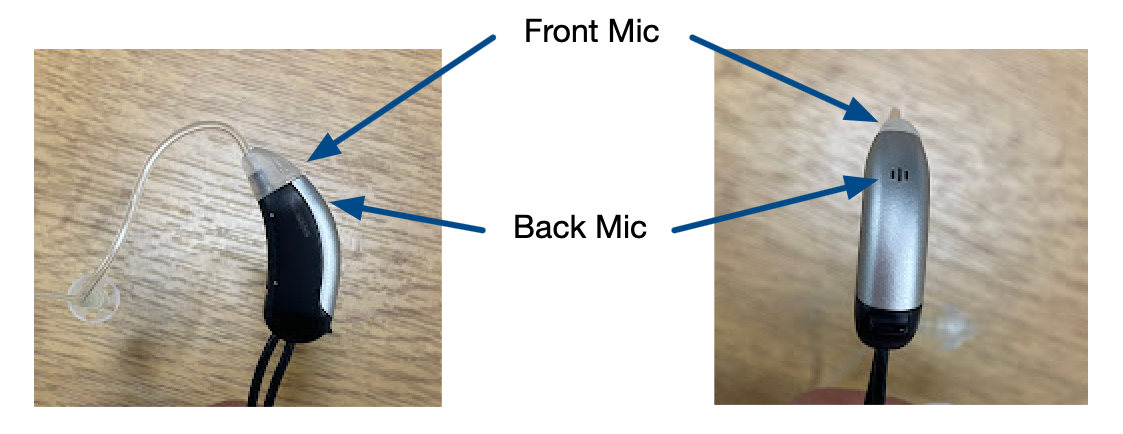
ariacontains WAV files with 7-channel recordings, with a 48 kHz sampling rate. The stem of the audio file name will be used as ID of the recording in all the subsequent filenames and lists (<session-id>.aria.wav).hacontains WAV files with 4-channel recordings, with a 48 kHz sampling rate, named<session-id>.ha.wav. Channels 1 and 2 are the front microphones of the left and right hearing aid; channels 3 and 4 are the back microphones of the left and right hearing aid.ctcontains the close-talk mic WAV files with 48 kHz sampling rate. There are four single-channel signals<session-id>.ct_pos1.wav,<session-id>.ct_pos2.wav,<session-id>.ct_pos3.wavand<session-id>.ct_pos4.wav. The position numbers correspond to the wearer’s location at the table. The position number of the hearing aid and Aria wearer is available in the metadata.refcontains the reference signals for computing intrusive metrics. Separate references are provided for the Aria and the hearing aid.<session-id>.aria.pos1.wav, …,<session-id>.aria.pos4.wav,<session-id>.ha.pos1.wav, …,<session-id>.ha.pos4.wav, withposindicating the seating position. For convenience, symbolic links to the same files are provided named with the corresponding participant ID, e.g.,<session-id>ha.P001.wavetc. The reference is a single-channel audio file with the duration of the session. The metadata contains a csv file identifying the valid speech regions within each reference file.trackercontains the head tracking data as a separate csv file for each participant:<session-id>.tracker_pos1.csv,<session-id>.tracker_pos2.csv,<session-id>.tracker_pos3.csvand<session-id>.tracker_pos4.csv. The position index has the same meaning as for the close-talk mic data. Within each csv file, there are six column, TX, TY, TZ, RX, RY and RZ, giving the locations and orientations of the heads at a 250 Hz framerate. The data is in mm and radians using ahelicalangle convention.participantcontains WAV files for each participant storing the participant’s reading of the ‘Rainbow passage’ that can be used for obtaining a speaker embedding. The files are named<participant-id>.wav. The metadata records theparticipant-idand seat number of each participant in each session.metadata- Metadata for each session, identifying participants in each position in each session and indicating who is wearing Aria glasses and hearing aids. (Note, the Aria glasses and hearing aids were moved to different seat positions for each session. They are never both worn by the same participant.)metadata/ref- Containscsvfiles that give the start and end sample of each valid speech region in the reference file. These are the regions over which the speech metrics will be computed. The files are named<session-id>.<device>.<position>.csv. For convenience, symbolic links to the same data are provided with the names<session-id>.<device>.<participant-id>.csvwhereparitcipant-idis the id of the participant sitting at the position, and correspond to the IDs used for theparticipantWAV files.
During test time, systems can only make use of the aria, ha and participant data plus the metadata that identifies the participants in the session. The ct and tracker data can only be used during training, and the ref and metadata\ref data can only be used for analysis or evaluation purposes.
Metadata files
In addition to the reference csv files, the metadata directory also contains session csv files, session.<datasplit>.csv. These provide the participant ID of the participant at each seating position, and also indicate the seat position of the wearer of the hearing aids and aria glasses. These have the following format,
session,aria_pos,ha_pos,pos1,pos2,pos3,pos4
train_01,3,4,P005,P007,P008,P006
train_02,4,3,P011,P010,P009,P012
train_03,1,2,P014,P016,P015,P013
train_04,1,2,P029,P030,P031,P032
...
So for example, for session train_01, the Aria glasses are worn by the participant in position 3 (P008), and the hearing aids by the participant at position 4 (P006). Note, the Aria glasses were not available for three of the training sessions: train_16, train_28 and train_29 . This is indicated in the metadata file by the position number being omitted from the aria_pos column for these rows.
Hearing aid devices
The hearing aid (HA) devices have two microphones (front and back) for the left and right ear, to give a total of four channels. The hearing aid signals are preamplified and then connected to the same audio interface as the close talk (CT) microphones allowing for sample alignment across all HA and CT channels.
The figure below shows the same device from two different orientations with the approximate locations of the front and back microphone indicated.
Aria Glasses
Detailed information on the Aria glasses can be found at the website of the Aria project, especially in the documentation.
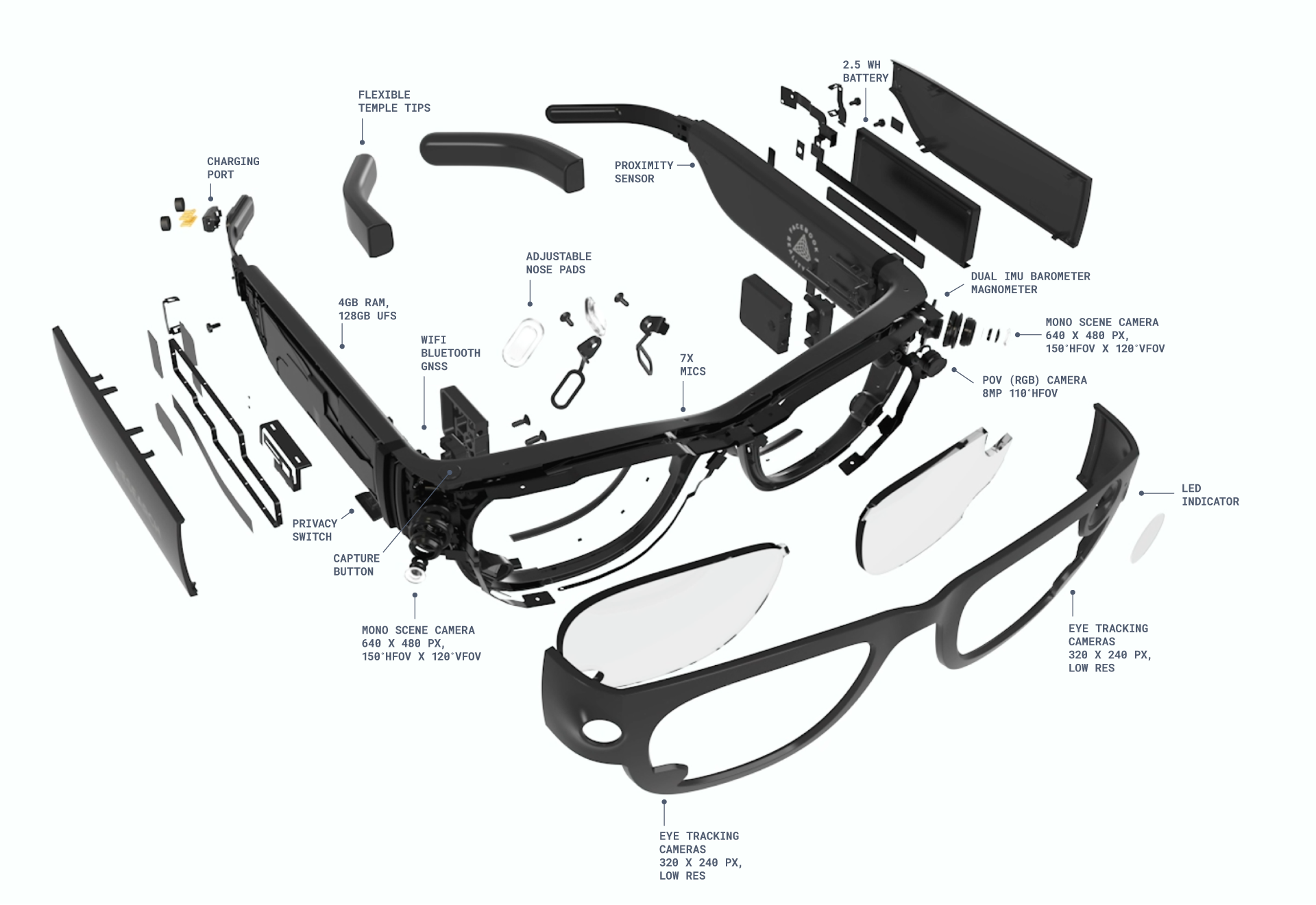
Two sizes of Aria Glasses were used ‘Large’ and ‘Small’ chosen according to which fit the participant most comfortably. The microphone geometry for the Large glasses is as follows.
| position | x [cm] | y [cm] | z [cm] |
|---|---|---|---|
| back → front | right → left | bottom → up | |
| lower-lens right | 9.95 | -4.76 | 0.68 |
| nose bridge | 10.59 | 0.74 | 5.07 |
| lower-lens left | 9.95 | 4.49 | 0.76 |
| front left | 9.28 | 6.41 | 5.12 |
| front right | 9.93 | -5.66 | 5.22 |
| rear right | -0.42 | -8.45 | 3.35 |
| rear left | -0.48 | 7.75 | 3.49 |
The Aria audio signal is recorded to storage on the glasses. After each session, these signals are recovered. Note, there is a clock drift between the Aria glasses and the MOTU audio interface that was used to record all other audio signals. This drift occurs at a rate of approximately 100 ms per hour and has been carefully estimated per session to facilitate signal (i.e., see Reference Signal construction below).
Reference Signals
Reference signals are provided for training enhancement systems and evaluating performance. These signals approximate the clean, direct-path speech from conversation participants as received at the device microphones. Since this is real-world data (not simulated), references are constructed using close-talk microphones with the following process:
- Close-Talk Processing
- Directional close-talk mics are denoised to reduce background leakage
- High SNR is maintained before/after processing
- Speech Segmentation
- SileroVAD identifies active speech regions
- Delay & Synchronization
- Propagation delay: Calculated using head-tracker distance measurements between speaker and listener
- Clock drift correction (Aria only): Linear compensation applied between Aria/close-talk clocks
- Fine Alignment
- ±2ms adjustment via cross-correlation with device mics:
- Aria: Nose bridge microphone
- Hearing aids: Computed for front left/right mics then averaged
- ±2ms adjustment via cross-correlation with device mics:
- Reference Assembly
- Time-aligned segments are summed to create single-channel references
Key Characteristics:
- 📌 Format: Single-channel (despite multi-channel devices)
- ⚠️ Limitations:
- No microphone/HRTF characteristic compensation
- Quality depends on close-talk denoising performance
- Spatial effects not captured
- Time-delays modelled using average over the speech segment
- ✅ Suitable for:
- Training objectives
- STOI and similar metrics
- STFT-based loss functions
- ❌ Not suitable for:
- Metrics requiring exact multi-channel reproduction
- Binaural/HRTF evaluation
Tracker Data
The head tracking data is stored in CSV files named <session-id>.tracker_<pos>.csv. Where pos can be pos1, pos2, pos3 or pos4 and indicates the seat of the participant being tracked. The CSV file has the following format:
RX, RY, RZ, TX, TY, TZ
0.113541,0.037043,2.332312,299.732452,-155.289459,1320.493652
0.114847,0.035577,2.331669,299.915100,-155.544464,1320.511963
0.115966,0.033263,2.329266,300.026062,-155.711182,1320.475342
0.118553,0.032524,2.330051,300.332703,-156.053162,1320.554688
0.120550,0.031226,2.329265,300.456024,-156.267731,1320.530640
0.122704,0.029718,2.328243,300.627594,-156.503647,1320.539795
...
The tracking data provides the position and orientation of the tracking hat that is being worn by each participant. Each row represents a successive frame at a frame rate of 250 Hz. The data has been carefully synchronised with the start of the audio recordings. The RX, RY and RZ present the orientation as a rotation stored using a helical format. i.e. the vector RX, RY, RZ is in the direction of the axis of the rotation, and the magnitude of the vector equals the angle of the rotation measured in radians. The TX, TY and TZ give the world coordinations of the tracking objects ‘origin’ measured in millimeters.
The geometry of the object being tracked is stored in Vicon VSK files in the metadata directory. These files specify the object’s coordinate system with its origin and the location of its constituent markers.
Using the tracking data and the VSK file, the trajectory of the individual markers can be reconstructed. The figure below shows a 5-second animation of typical participant head motion from a recording session. This has been reconstructed from the tracker CSV file and using the VSK files to reconstruct the individual marker positions
![]()
Getting the data
The data has been partitioned into three compressed tar files.
- CHiME-9 ECHI Dev:
- Includes dev data signals for HA and Aria plus essential metadata
- chime9_echi_dev.tar.gz [~23.6GB]
- CHiME-9 ECHI Train:
- Includes all the training data signals for HA and Aria.
- chime9_echi.train_pt1.v1_0.tar.gz [~30GB]
- chime9_echi.train_pt2.v1_0.tar.gz [~37GB]
(The training data has been split into two parts to keep within HuggingFace’s 50 GB max file size. Please download both).
For obtaining the CHiME-9 ECHI dataset, you first need to request access and then download it using your Hugging Face token. Please note that access requires signing a Data Use Agreement.
- Request Access:
- Go to the CHiME-9 ECHI dataset repository on Hugging Face.
- Request access to the dataset. You will need a Hugging Face account.
-
Get Your Hugging Face Token:
If you don’t have one, create a Hugging Face User Access Token. Follow the instructions here to obtain your
HF_TOKEN. Make sure it has read permissions. -
Download and Untar Dataset Files:
It’s recommended to download and untar the data into a
datadirectory within yourCHiME9-ECHIproject folder. (See baseline.md.)
# Navigate to your baseline project directory if you aren't already there
# cd CHiME9-ECHI
# Create a data directory (if it doesn't exist)
mkdir -p data
cd data
# Export your Hugging Face token (replace 'your_actual_token_here' with your actual token)
export HF_TOKEN=your_actual_token_here
# Download the development set
wget --header="Authorization: Bearer $HF_TOKEN" https://huggingface.co/datasets/CHiME9-ECHI/CHiME9-ECHI/resolve/main/data/chime9_echi.dev.v1_0.tar.gz
# Untar the downloaded files
tar -zxovf chime9_echi.dev.v1_0.tar.gz
The training data is split into two parts and can be downloaded similarly
wget --header="Authorization: Bearer $HF_TOKEN" https://huggingface.co/datasets/CHiME9-ECHI/CHiME9-ECHI/resolve/main/data/chime9_echi.train_pt1.v1_0.tar.gz
wget --header="Authorization: Bearer $HF_TOKEN" https://huggingface.co/datasets/CHiME9-ECHI/CHiME9-ECHI/resolve/main/data/chime9_echi.train_pt2.v1_0.tar.gz
# Untar the downloaded files
tar -zxovf chime9_echi.train_pt1.v1_0.tar.gz
tar -zxovf chime9_echi.train_pt2.v1_0.tar.gz
Unpack all files from the same root directory. Note that the ‘-o’ (overwrite) flag is needed because some small files, e.g. the metadata, are stored redundantly in each tar file for convenience, so they should be allowed to overwrite when unpacking.
License and Data Use Agreement
Dataset: CHiME-9 ECHI (Enhancing Conversations to address Hearing Impairment) Dataset
Version: June 2025
Maintained by: CHiME-9 ECHI Challenge Organizers
Contact: chime9-echi@gmail.com
This dataset contains sensitive audio recordings, including identifiable speech of multiple speakers.
Use of this dataset is restricted under the terms of the CHiME-9 ECHI Data Use Agreement.
✅ Permitted Uses
- Academic and educational purposes
- Algorithm development and benchmarking
- Publication of models and results with attribution
❌ Prohibited Uses
- Redistribution of raw data (video, audio, face landmarks, transcripts)
- Uploading the dataset to public cloud or sharing platforms
- Biometric surveillance, re-identification, or profiling
📚 Citation
If you use this dataset, cite:
Sutherland, R., Clarke, J., Elghazaly, H., Kuebert, T., Lugger, M., Petrausch, S., Azcarreta Ortiz, J., Xu, B., Goetze, S. and Barker, J., “Descriptor: Enhancing Conversations for the Hearing Impaired in the 9th Computational Hearing in Multisource Environments Challenge (CHiME9 ECHI),” in IEEE Data Descriptions, vol. 3, pp. 73-81, 2026, doi: 10.1109/IEEEDATA.2025.3647612.
BibTeX
@ARTICLE{11314168,
author={Sutherland, Robert and Clarke, Jason and Elghazaly, Hend and Kuebert, Thomas and Lugger, Marko and Petrausch, Stefan and Ortiz, Juan Azcarreta and Xu, Buye and Goetze, Stefan and Barker, Jon},
journal={IEEE Data Descriptions},
title={Descriptor: Enhancing Conversations for the Hearing Impaired in the 9th Computational Hearing in Multisource Environments Challenge (CHiME9 ECHI)},
year={2026},
volume={3},
pages={73-81},
doi={10.1109/IEEEDATA.2025.3647612}
}
⚠️ Legal & Ethical Requirements
- Comply with applicable laws including the GDPR (EU data protection law)
- Follow your institution’s research ethics process (e.g., IRB review)
- Do not attempt to re-identify individuals, especially minors
- Store data securely in access-controlled environments