Overview
- 1-channel, 2-channel, or 6-channel microphone array data (subset of the channels of the CHiME-3 data),
- real acoustic mixing, i.e. talkers speaking in challenging noisy environments,
- four varied noise settings: café, street junction, public transport and pedestrian area.
The recording set up
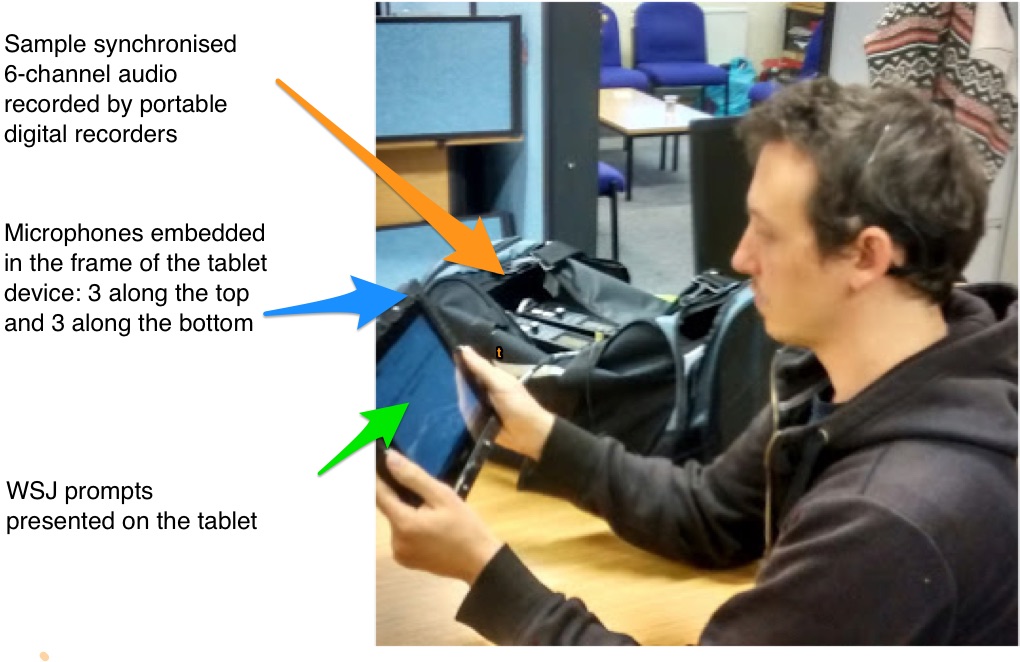
WSJ prompts are read from a tablet device. Speech is captured by 6 microphones embedded in the frame and recorded in 24-bits at 48 kHz by a TASCAM DR-680 multi-track field recorder. A separate close-talking microphone channel has also been recorded. Audio was subsequently downsampled to 16-bit 16 kHz for distribution.
The microphone configuration
The figure below shows the recording device and indicates the positions of the microphones. The microphones are numbered 1 to 6 corresponding to channels 1 to 6 in audio available for download. The microphones labeled in green are facing forward and are mounted flush with the front of the frame. Microphone 2, labeled in blue, faces backwards and is mounted flush with the back of the 1.0 cm thick frame. The microphones were audio-technica ATR3350 omnidirectional lavalier mics.

All 6 tablet microphones were recorded on the same TASCAM unit and are therefore sample synchronised. The close-talking microphone (channel 0) was a Beyerdynamic condenser headset microphone recorded on a separate TASCAM unit daisy-chained to the first. Synchronisation between the close-talking mic and the tablet mics is only approximate, +-20 ms.
Microphone failures
Similarly to a commercial device, a number of the tablet microphones occasionally failed to record properly due to hardware issues or to masking by the user's hands or clothes. These failures affect 12% of all the real data and mainly concentrate on channels 4 and 5, and on the BUS, STR and PED environments. The channels used in the development and test data for the 1-channel and 2-channel tracks were chosen in such a way that microphone failures do not arise. Such failures do arise, however, in the development and test data for the 6-channel track and in the training data for all tracks.
Automatically detecting microphone failures is part of the challenge. The enhancement baseline (BeamformIt) implicitly discards channels for which the microphone failed, but participants might find better solutions based on, e.g., measuring the correlation between channels.
The recording procedure
The original live recordings have been made by 12 US talkers (6 male and 6 female). For each talker recordings were made first in a sound proof booth and then in each of the four noisy target environments. About 100 sentences were read in each location. The talkers used a simple interface that presented WSJ prompts on the tablet. It was stressed that each sentence had to be read correctly and without interruption. Talkers were allowed as many attempts as necessary to read each sentence. They were asked to use the tablet in whatever way felt natural and comfortable but they were encouraged to adjust their reading position after each 10 utterances, e.g. either holding the tablet (most typical), resting it on their lap, laying it on a table, etc.
The recordings have been divided into training, dev test and eval test sets. Each set features different talkers and different instances of the same noise environment, e.g., all data sets feature the cafés noise environment but different specific cafés are used in each set. For full details of the data sets please continue to the next page.