Baseline System
The CHiME-7 DASR Baseline is implemented as an ESPNet2 recipe
There are two sub-folders asr1 and diar_asr1. The first contains the baseline for the acoustic robustness sub-track, the second the baseline for the main track.
Most of the code is shared among the two as basically the main track consists of an additional diarization module.
The challenge baseline consists of multi-channel diarization (not used in the acoustic robustness sub-track, as there oracle diarization can be used), channel selection via envelope variance [1], guided source separation [2] and ASR, as depicted here below:
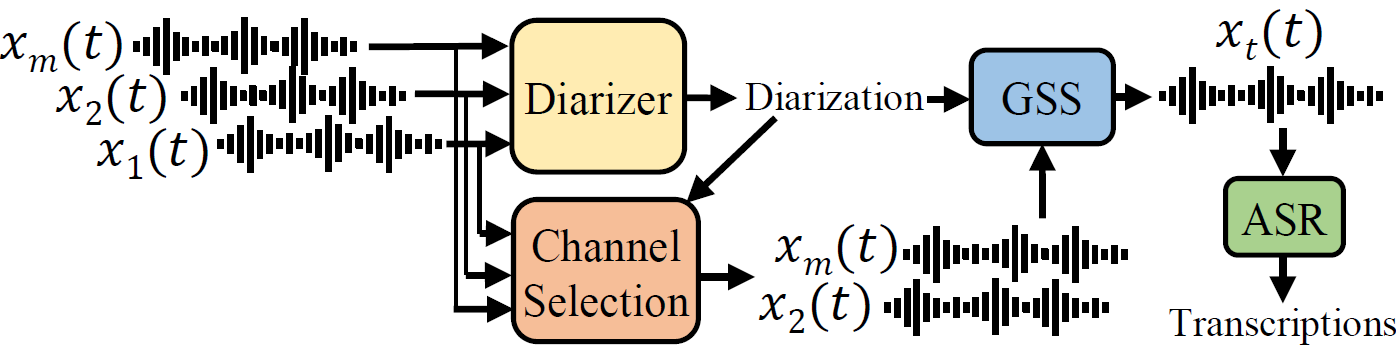
More in detail it consists:
- Diarizer: the diarizer module performs multi-channel diarization and is used to obtain utterance-wise segmentation for each speaker.
Here we use a system based on Pyannote diarization pipeline [1], [2] modified to handle multiple channels.
For the acoustic robustness sub-track this system is avoided and oracle diarization is used.
Note that we also provide, for CHiME-6, word-level alignment that you can use in place of the manual oracle diarization CHiME7_DASR_falign (can be used also for training).
Following, the last three components are shared between the main track and the optional acoustic robustness sub-track.
- Guided Source Separation (GSS) [3], here we employ the GPU-based version (much faster) from Desh Raj.
- End-to-end ASR model based on [4], which is a transformer encoder/decoder model trained
with joint CTC/attention [5]. It uses WavLM [6] as a feature extractor. - Optional Automatic Channel selection based on Envelope Variance Measure (EV) [7].
Important
In the CHiME-7 DASR baseline ESPNet folder you can find also the scripts that are necessary for generating the CHiME-7 DASR official datasets as well as detailed instructions on how to generate the data.
Please follow the instructions provided in the ESPNet2 acoustic subtrack recipe README.md, where we also briefly describe the baseline system more in detail.
Pyannote-based Diarization System
As said this diarization system is based on Pyannote diarization pipeline as described in this technical report.
It is a very effective diarization system that uses a local EEND-based segmentation model [1] and leverages this model for extracting overlap-aware embeddings.
Here we use the pre-trained Pyannote diarization pipeline and fine-tune only the segmentation model Pyannote segmentation model on CHiME-6 training data (using Mixer 6 speech dev for validation).
We found that fine-tuning using the CHiME-6 manual annotation was better than using the CHiME-6 forced-alignment annotation, which is made available, also for the training set here.
The fine-tuned segmentation model is available in HuggingFace: popcornell/pyannote-segmentation-chime6-mixer6
Extension to multiple channels
Here, since multiple channels are available, we run the segmentation model on all the channels and then select the best channel based on the output of the segmentation model (the channel with the most speech activity is chosen).
Then only the best channel is used for diarization. Note that this happens for each different 5 second chunk.
This very crude selection policy assumes that the segmentation model is very robust against noisy channels.
It also does not account for the fact that one speaker could be prevalent in one channel while another in another channel.
It was mainly chosen due to the fact that it keeps the inference very fast (opposed to e.g. using all channels for clustering or top-k in clustering).
There is then a lot to improve upon.
Acoustic Robustness Sub-Track: Oracle Diarization + ASR
Pretrained model: popcornell/chime7_task1_asr1_baseline
Detailed decoding results (insertions, deletions etc) are available in baseline_logs/RESULTS.md here.
Note that WER figures in asr1/baseline_logs/RESULTS.md and in the model card in popcornell/chime7_task1_asr1_baseline will be different slightly (a bit higher) from the diarization-attributed WER (DA-WER) score we use for ranking. This latter, as cpWER [1], is based on concatenated utterances for each speaker and is thus different from WER computed by considering each utterance.
The final score is described in task main page and is similar to the one used in previous CHiME-6 Challenge except that it is not permutation invariant now, but the speaker mapping is instead assigned via diarization (hence diarization-assigned WER).
Here we report the results obtained using channel selection (retaining 80% of all channels) prior to performing GSS and decoding with the baseline pre-trained ASR model. This is the configuration that gave the best results overall on the dev set. Output of the evaluation script (More detailed results for each scenario are available here).
The final ranking score for the baseline is 0.288 macro averaged DA-WER for the acoustic robustness sub-track.
###################################################
### Metrics for all Scenarios ###
###################################################
+----+------------+---------------+---------------+----------------------+----------------------+--------+-----------------+-------------+--------------+----------+
| | scenario | num spk hyp | num spk ref | tot utterances hyp | tot utterances ref | hits | substitutions | deletions | insertions | wer |
|----+------------+---------------+---------------+----------------------+----------------------+--------+-----------------+-------------+--------------+----------|
| 0 | chime6 | 8 | 8 | 6644 | 6644 | 42748 | 11836 | 4297 | 3090 | 0.326472 |
| 0 | dipco | 20 | 20 | 3673 | 3673 | 22125 | 5859 | 1982 | 2212 | 0.33548 |
| 0 | mixer6 | 118 | 118 | 14804 | 14804 | 126617 | 16012 | 6352 | 7818 | 0.20259 |
+----+------------+---------------+---------------+----------------------+----------------------+--------+-----------------+-------------+--------------+----------+
####################################################################
### Macro-Averaged Metrics across all Scenarios (Ranking Metric) ###
####################################################################
+----+---------------+---------------+---------------+----------------------+----------------------+--------+-----------------+-------------+--------------+----------+
| | scenario | num spk hyp | num spk ref | tot utterances hyp | tot utterances ref | hits | substitutions | deletions | insertions | wer |
|----+---------------+---------------+---------------+----------------------+----------------------+--------+-----------------+-------------+--------------+----------|
| 0 | macro-average | 48.6667 | 48.6667 | 8373.67 | 8373.67 | 63830 | 11235.7 | 4210.33 | 4373.33 | 0.288181 |
+----+---------------+---------------+---------------+----------------------+----------------------+--------+-----------------+-------------+--------------+----------+
Such baseline system would rank third on dev set based on the rules of the past CHiME-6 Challenge on Track 1 (unconstrained LM). Results on the evaluation set will be released after the end of the CHiME-7 DASR Challenge.
Note that as explained in CHiME-7 DASR website Data page the evaluation set for CHiME-6 is different from the one in previous edition and is supposed to be more challenging.
Main Track Results
We report the results with this Pyannote-based multi-channel pipeline hereafter (as obtained with the challenge evaluation script).
More detailed results for each scenario are available here.
The final ranking score for the baseline is 0.472 macro-averaged DA-WER in the main track, the DER and JER (macro-averaged) are respectively 0.288 and 0.385.
###################################################
### Metrics for all Scenarios ###
###################################################
+----+------------+---------------+---------------+----------------------+----------------------+--------------------+----------+-----------+-------------+---------------+--------------------------+-----------------+-----------------+----------------------+--------+-----------------+-------------+--------------+----------+
| | scenario | num spk hyp | num spk ref | tot utterances hyp | tot utterances ref | missed detection | total | correct | confusion | false alarm | diarization error rate | speaker error | speaker count | Jaccard error rate | hits | substitutions | deletions | insertions | wer |
|----+------------+---------------+---------------+----------------------+----------------------+--------------------+----------+-----------+-------------+---------------+--------------------------+-----------------+-----------------+----------------------+--------+-----------------+-------------+--------------+----------|
| 0 | chime6 | 8 | 8 | 3321 | 6643 | 3021.8 | 13528.8 | 8544.78 | 1962.19 | 424.44 | 0.399772 | 4.09521 | 8 | 0.511901 | 27149 | 11830 | 19902 | 5013 | 0.624055 |
| 0 | dipco | 20 | 20 | 2251 | 3673 | 939.43 | 7753.04 | 5804.02 | 1009.59 | 365.67 | 0.298553 | 8.28111 | 20 | 0.414056 | 16614 | 7137 | 6215 | 3622 | 0.566442 |
| 0 | mixer6 | 141 | 118 | 9807 | 14803 | 6169.91 | 44557.9 | 37631.8 | 756.2 | 455.37 | 0.165661 | 26.9167 | 118 | 0.228108 | 122549 | 14000 | 12432 | 7210 | 0.225814 |
+----+------------+---------------+---------------+----------------------+----------------------+--------------------+----------+-----------+-------------+---------------+--------------------------+-----------------+-----------------+----------------------+--------+-----------------+-------------+--------------+----------+
####################################################################
### Macro-Averaged Metrics across all Scenarios (Ranking Metric) ###
####################################################################
+----+---------------+---------------+---------------+----------------------+----------------------+--------------------+---------+-----------+-------------+---------------+--------------------------+-----------------+-----------------+----------------------+---------+-----------------+-------------+--------------+----------+
| | scenario | num spk hyp | num spk ref | tot utterances hyp | tot utterances ref | missed detection | total | correct | confusion | false alarm | diarization error rate | speaker error | speaker count | Jaccard error rate | hits | substitutions | deletions | insertions | wer |
|----+---------------+---------------+---------------+----------------------+----------------------+--------------------+---------+-----------+-------------+---------------+--------------------------+-----------------+-----------------+----------------------+---------+-----------------+-------------+--------------+----------|
| 0 | macro-average | 56.3333 | 48.6667 | 5126.33 | 8373 | 3377.05 | 21946.6 | 17326.9 | 1242.66 | 415.16 | 0.287995 | 13.0977 | 48.6667 | 0.384688 | 55437.3 | 10989 | 12849.7 | 5281.67 | 0.472104 |
+----+---------------+---------------+---------------+----------------------+----------------------+--------------------+---------+-----------+-------------+---------------+--------------------------+-----------------+-----------------+----------------------+---------+-----------------+-------------+--------------+----------+
We can see that the DER and JER values are quite competitive on CHiME-6 with the state-of-the-art but the WER figures are quite poor.
Note that here we report DER and JER which are computed against manual annotation with 0.25 seconds collar for CHiME-6.
The DER and JER obtained with respect to the forced-alignment annotation are a bit lower actually (38.94%).
Note that the previous challenge used no DER and JER collars e.g. the Kaldi TS-VAD implementation obtains around 44% DER with respect to forced alignment annotation with no collar.
This same model achieves around 54% DER w.r.t. the same annotation but it is because it is optimized towards looser segmentation which we found it yielded better WER especially on Mixer 6 compared to optimizing the pipeline towards lower DER w.r.t. forced alignment no collar ground truth.
The high WER figures may due to the fact that we use an E2E ASR system which may be more sensitive to segmentation errors compared to hybrid ASR models. We found that using an higher weight in decoding for CTC helped a bit (we use here 0.6, see conf/decode_asr_transformer.yaml).
On the other hand, using ESPNet2 E2E ASR allows to keep the baseline arguably simpler (than e.g. Kaldi) and allows more easily to explore some techniques such as serialized output training, target speaker ASR and E2E integration with speech enhancement and separation front-ends.
But you are free to explore other techniques (e.g. by using K2, which is also integrated with lhotse, used in this recipe for data preparation).
It is worth to point out also that it is quite challenging to optimize the diarization hyper-parameters (for example merging the segments that are X apart) for all three scenarios.
E.g. best parameters for CHiME-6 lead to degradation to Mixer 6 performance.
Contact/Stay Tuned
If you are considering participating or just want to learn more then please join the CHiME Google Group.
We have also a CHiME Slack Workspace.
Follow us on Twitter, we will also use that to make announcements.
References
[1] Bredin, Hervé, and Antoine Laurent. “End-to-end speaker segmentation for overlap-aware resegmentation.” arXiv preprint arXiv:2104.04045 (2021).
[2] Bredin, Hervé, et al. “Pyannote. audio: neural building blocks for speaker diarization.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.
[3] Boeddeker, C., Heitkaemper, J., Schmalenstroeer, J., Drude, L., Heymann, J., & Haeb-Umbach, R. (2018, September). Front-end processing for the CHiME-5 dinner party scenario. In CHiME5 Workshop, Hyderabad, India (Vol. 1).
[4] Chang, X., Maekaku, T., Fujita, Y., & Watanabe, S. (2022). End-to-end integration of speech recognition, speech enhancement, and self-supervised learning representation. https://arxiv.org/abs/2204.00540
[5] Kim, S., Hori, T., & Watanabe, S. (2017, March). Joint CTC-attention based end-to-end speech recognition using multi-task learning. Proc. of ICASSP (pp. 4835-4839). IEEE.
[5] Chen, S., Wang, C., Chen, Z., Wu, Y., Liu, S., Chen, Z., … & Wei, F. (2022). Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16(6), 1505-1518.
[7] Wolf, M., & Nadeu, C. (2014). Channel selection measures for multi-microphone speech recognition. Speech Communication, 57, 170-180.