Data
![]()
The data consists of a two datasets:
- A meeting recordings dataset for benchmarking and training.
- A simulated training dataset.
See below for License.
Download
Refer to the NOTSOFAR GitHub for download instructions.
Meetings recordings dataset
The following table summarizes our dataset with single-channel (SC) and multi-channel (MC) recordings, corresponding to the challenge tracks.
| Train set 1 | Train set 2 | Train set 3 (formerly Dev set 1) | Dev set (formerly Dev set 2) | Eval set (blind) | |
|---|---|---|---|---|---|
| Number of meetings | 37 | 40 | 36 | 33 | 80 |
| Meeting duration | 6 minutes (avg.) | ||||
| Devices (SC / MC) | 5 / 4 | 5 / 4 | 5 / ~3 | ~4 / ~4 | 2 / 2 |
| Sessions (SC / MC) | 185 / 148 | 200 / 160 | 177 / 106 | 117 / 130 | 160 / 160 |
| Hours (SC / MC) | 18 / 14 | 20 / 16 | 17 / 10 | 11 / 13 | 16 / 16 |
| Total number of rooms | 20 rooms | ~10 rooms | |||
| Total number of participants | 22 participants | ~10 participants | |||
- Although multiple devices were used for recording, during inference the NOTSOFAR challenge restricts processing to just one device (session).
- The Evaluation set is entirely disjoint from the Training and Development sets, with no overlap in participants or rooms.
- Dev-set-1 and the Training sets share most of their participants. Users of Dev-set-1 should be mindful of overfitting to specific participants.
- Dev-set-2 includes mostly new participants compared to the Training sets and Dev-set-1, but there are still some overlapping participants. Namely: ‘Jim’, ‘Walter’, ‘David’, ‘Jerry’. It is advised not to use those participants for training so that dev-set-2 remains a reliable estimate of performance.
- For the dataset release schedule see Challenge Important Dates. Upon the release of Dev-set-2, we will unveil the ground truth for Dev-set-1. Dev-set-2 will become the official dev set, and Dev-set-1 will join the training set.
Role-play meeting topics
Meetings are role-played by the participants. Most meetings feature semi-professional topics, in which participants role-play as professionals discussing a work-related issue. For example, a cruise ship company planning an event, administrators planning a city park, or users complaining about IT problems. Some meetings feature non-work-related topics, such as favorite TV shows, debating whether to raise kids as vegetarians, or friends sharing recipes.
Sample recording and transcription
This is a sample recording from a single channel stream. The meeting participants are discussing ways to recruit more employees.
Transcription
| start_time | end_time | speaker_id | text |
|---|---|---|---|
| 9.71 | 11.3 | Sophie | <ST/> people to come work with us. |
| 11.41 | 15.09 | Sophie | So what can we change about our business about the way that we treat our uh <ST/> |
| 15.8 | 18.56 | Sophie | <ST/> um workers in order to get more people to come. |
| 18.75 | 22.1 | Jim | I think if we take better care of the workers you know like <ST/> |
| 21.23 | 21.92 | Sophie | How so? |
| 22.18 | 29.18 | Jim | <ST/> well for such you know like provide more things like food or free activities in the office, I think a lot more people would like to come. |
| 27.07 | 27.71 | Sophie | Mm-hmm. |
| 29.38 | 29.81 | Sophie | Yeah. |
| 29.97 | 32.22 | Sophie | Like if there was like maybe muffins in the morning. |
| 32.42 | 33.08 | Jim | Yeah. |
| 32.7 | 33.17 | Bert | Yes. |
| 32.99 | 35.86 | Sophie | <ST/> or free coffee or something, you know people would <ST/> |
| 34.54 | 35.31 | Jim | Definitely. |
| 35.06 | 35.42 | Bert | Yes. |
| 35.75 | 36.43 | Bert | Yeah. But how? |
| 36.59 | 37.65 | Sophie | <ST/> be more eager to come. |
| 37.64 | 38.16 | Jim | Yeah. |
| 38.21 | 42.4 | Bert | We need to get people to get in to the front door in the first place, so that's the problem as we need people. |
| 41.69 | 44.21 | Sophie | Well yeah, when you have like these thing they'll lure people in you know. |
| 42.31 | 42.76 | Jim | Yup. |
| 43.8 | 49.34 | Jim | Exactly. People hear about this from their friends that work here or we could have like you know um <ST/> |
| 44.42 | 45.06 | Bert | Mmm. Well. |
| 46.05 | 46.6 | Bert | OK. |
| 49.44 | 54.48 | Jim | <ST/> a page in one of the social networks showing a life at our company and how great that is. |
Experimental setup
The following images show the setup for recording the NOTSOFAR meetings dataset.
Experimental setup overview
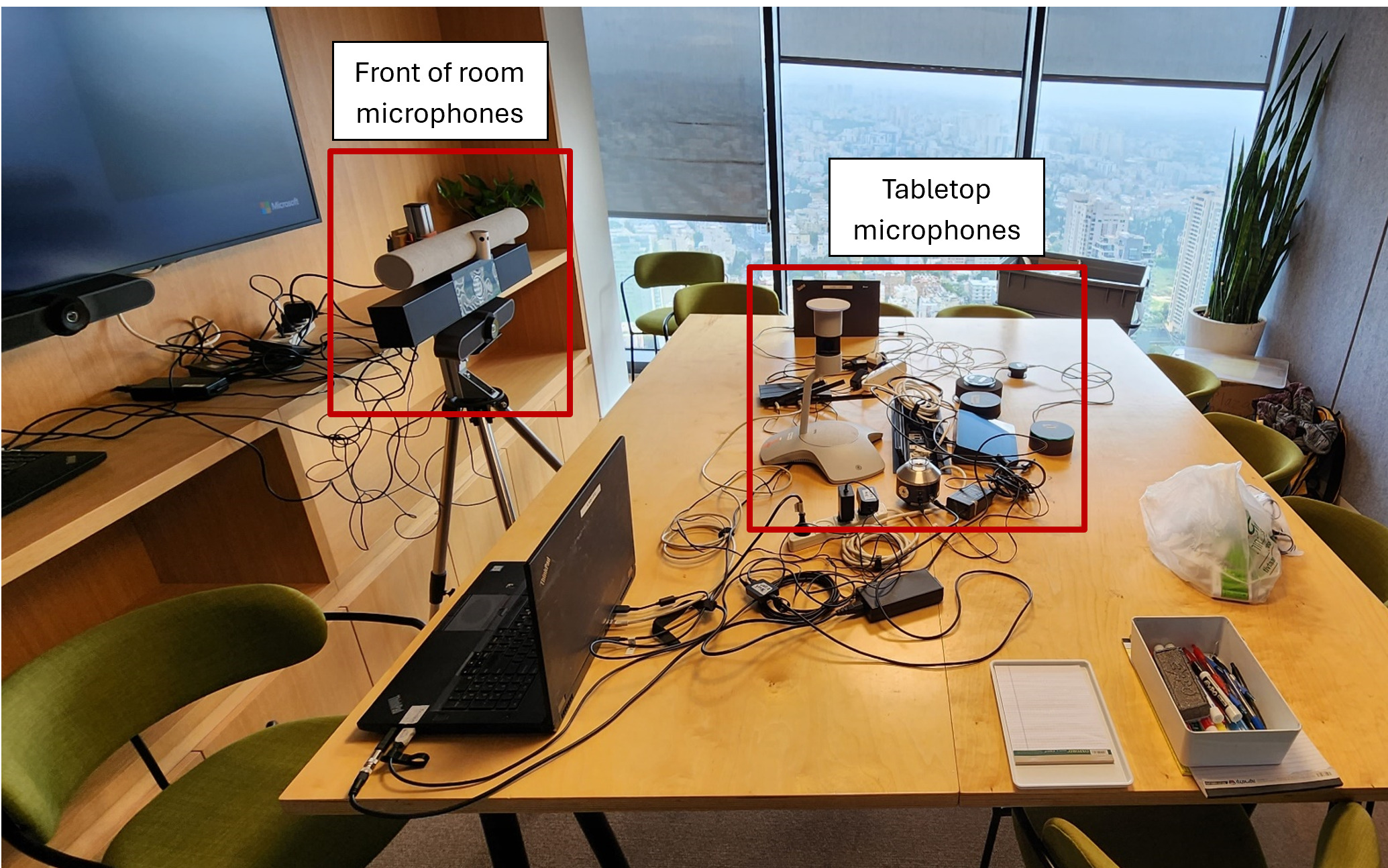
| Front of room devices | Tabletop devices |
|---|---|
 |  |
|
|
Tabletop items
Laptops and personal items next to the microphones contribute to the authentic acoustic properties of the recordings.

Close talk recorders
Mobile voice recorder, head mounted microphone and throat microphone.

Sample meeting images


Directory structure
The audio data and the transcriptions follow this directory structure:
240130.1_train
└───MTG
├───MTG_30830
│ │ devices.json
│ │ gt_meeting_metadata.json (*)
│ │ gt_transcription.json (*)
│ │
│ ├───close_talk (*)
│ │ CT_21.wav
│ │ CT_22.wav
│ │ CT_23.wav
│ │ CT_25.wav
│ │
│ ├───mc_plaza_0
│ │ ch0.wav ... ch6.wav
│ │
│ ├───mc_rockfall_0
│ │ ch0.wav ... ch6.wav
│ │
│ ├───mc_rockfall_1
│ │ ch0.wav ... ch6.wav
│ │
│ ├───mc_rockfall_2
│ │ ch0.wav ... ch6.wav
│ │
│ ├───sc_meetup_0
│ │ ch0.wav
│ │
│ ├───sc_plaza_0
│ │ ch0.wav
│ │
│ ├───sc_rockfall_0
│ │ ch0.wav
│ │
│ ├───sc_rockfall_1
│ │ ch0.wav
│ │
│ └───sc_rockfall_2
│ ch0.wav
│
├───MTG_30831
:
├───MTG_30832
:
240130.1_dev
└───MTG
├───MTG_30830
:
(*) Ground truth and metadata are only published for the Training Set meetings initially.
MTG_30830
A directory containing the data for this meeting.
devices.json
A file that lists the audio devices for this meeting. For example:
[
{
"device_name":"CT_21",
"is_mc":false,
"is_close_talk":true,
"channels_num":1,
"wav_file_names":"close_talk/CT_21.wav"
},
{
"device_name":"plaza_0",
"is_mc":true,
"is_close_talk":false,
"channels_num":7,
"wav_file_names":"mc_plaza_0/ch0.wav,mc_plaza_0/ch1.wav, ..."
},
]
device_nameis the abbreviated alias device name. See the Recording devices table for the commercial name of each device.is_mcindicates multi-channel devices.is_close_talkindicates the close-talk devices. Each device records a single speaker’s head-mounted microphone.channels_numis the number of audio channels.wav_file_namesis a comma-delimited list of relative paths to this device’s audio files.
gt_meeting_metadata.json (* Training set only)
A file that contains metadata for this meeting. For example:
{
"meeting_id": "MTG_30830",
"MtgType": "mtg",
"MeetingDurationSec": 362.082625,
"Room": "ROOM_10002",
"NumParticipants": 4,
"ParticipantAliases": [
"Peter",
"Sophie",
"Olivia",
"Jim"
],
"Topic": "Should AI be used in schools?",
"Hashtags": "#NaturalMeeting",
"ParticipantAliasToCtDevice": {
"Peter": "CT_21",
"Sophie": "CT_22",
"Olivia": "CT_23",
"Jim": "CT_25"
}
}
Roomis the meeting room ID. See the Meeting rooms table for more information about each room.ParticipantAliasesare the meeting participant IDs. Participant are identified by first name aliases that are not their real names. The participants used these aliases to address each other during meetings. Each participant is identified by the same alias across all their meetings. The participant aliases are globally unique across all splits.Topicis a manually-labeled topic of the meeting.Hashtagsis a list of attributes for the meeting. See Metadata for details on each Hashtag.ParticipantAliasToCtDevicemaps participants to their close-talk audio devices, i.e. their personal head-mounted microphones.
gt_transcription.json (* Training set only)
A file containing the ground truth (GT) transcriptions. For example:
[
{
"speaker_id":"Peter",
"ct_wav_file_name":"close_talk/CT_21.wav",
"start_time":15.42,
"end_time":18.53,
"text":"I think schools are about preparing children for <ST/>",
"word_timing":[
[
"i",
15.47,
15.68
],
[
"think",
15.68,
16.12
],
...
]
},
...
]
Tags in GT transcriptions
| Tag | Definition |
|---|---|
<PName/> | Personal name |
<BA/> | Blank audio - an utterance with no word contents in the audio |
<FILL/> | Filled pause or false start |
<FILLlaugh/> | Laughter |
<ST/> | Sentence truncation |
<UNKNOWN/> | The audio is not intelligible |
<PAUSE/> | There is a long pause in speech, often with a significant non-speech sound (like breathing) |
<ISSUE/> | The audio is marked for future review |
close_talk (* Training set only)
A directory containing the close-talk recordings for each participant. These recordings are published for the Training set and initially withheld from the Development and Evaluation sets.
ch0.wav, ch1.wav
Audio files, one file per channel.
Recording devices
The recording devices are identified in the data files by an abbreviated alias. The following table lists the commercial name of each recording device.
| Device alias | Commercial name |
|---|---|
plaza_0 | Yealink SmartVision 60 |
rockfall_0 | EPOS Expand Capture 5 |
rockfall_1 | Yealink Intelligent Speaker |
rockfall_2 | Sennheiser TeamConnect Intelligent Speaker |
meetup_0 | Logitech MeetUp |
studio_0 | Poly Studio |
panacast_0 | Jabra PanaCast 50 |
CT_20, CT_21, … | Shure WH20 + TASCAM DR-40X Close Talk |
Missing device recordings
A few device recordings are missing from some meetings due to recording errors. See devices.json files for the list of available devices in each meeting.
The multi-channel recording of plaza_0 is available across all meetings in all datasets, therefore we suggest to use this device as a common reference for cross-meetings analyses.
Metadata
Meetings are labeled by their acoustic scenarios using hashtags in the file gt_meeting_metadata.json. The following table describes these hashtags.
All hashtags have a dominant effect throughout the meeting (e.g., #Coughing indicates frequent coughing), except when they specify a particular participant. For example, #TalkNearWhiteboard=ParticipantAlias means this specific participant talked near the whiteboard. Note that when computing WER over the entire meeting, the effect of talking near the whiteboard can be underrepresented since it is averaged with speakers who were “not near the whiteboard.”
| Hashtag | Description |
|---|---|
#NaturalMeeting | A meeting with no special instructions. |
#WalkAndTalk=ParticipantAlias | A participant is pacing around the room while speaking. |
#TalkNearWhiteboard=ParticipantAlias | A participant is speaking near the whiteboard, sometimes facing the board and sometimes facing the audience. |
#DebateOverlaps | Participants often speak in overlap, as in a heated debate or argument. |
#YesOkHmm | Frequent short utterances such as “Yes”, “Hmm”, “OK”, “Uhh” and other fillers are spoken in overlap with the main speaker. |
#TransientNoise= | Type and volume {low, high} of transient noise. Noises may come from the door, rummaging in bags, placing things on table, typing, etc. |
#WatchSlides | The participants are watching slides. They sometimes turn their faces towards the TV screen while speaking, and speak towards each other. |
#StandNearPlaza | Participants around the device plaza_0. |
#MoveInSeat | The participants move their heads or swivel in their seats while speaking. |
#StandSit | The participants are frequently toggling between standing up and sitting while talking. |
#LowTalkers=ParticipantAlias | A participant speaks in a soft tone with low volume. |
#FarLowTalker=ParticipantAlias | Someone speaks in a soft tone with low volume, and sits far from the device plaza_0. |
#Crowded | The participants sit shoulder-to-shoulder along one side of the table. This simulates the scenario where the meeting room is at full capacity. |
#LeaveAndJoin=ParticipantAlias | Someone leaves the meeting room and rejoins later, sometimes to a different seat. |
#TurnsNoOverlap | No speech overlap. Speakers take turns. |
#Coughing | Frequent coughing. |
#Laughing | Frequent laughing. |
#ShortTurnsOverlap | Short utterances, with overlaps in turns. |
#ReadText | Participants read text in turns with no overlaps. |
#LongMeeting= | Meeting duration in {minutes}. |
#Music | Music playing in the background (without vocals). |
Meeting participants
Meeting participants are native or near-native English speakers.
Each participant joined multiple meetings in the dataset. The Evaluation set participants did not participate in any Development set or Training sets meetings, thus they form a fully disjoint set of people. In contrast, the Development set and the Training set meetings share most of the same participants. Users of this dataset should be mindful of this and avoid creating models that over fit to specific participants.
Meeting rooms
The following table describes the Training set meeting rooms.
| Room Id | Seating Capacity | Length (cm) | Width (cm) |
|---|---|---|---|
| ROOM_10001 | 10 | 520 | 490 |
| ROOM_10002 | 11 | 600 | 410 |
| ROOM_10006 | 16 | 710 | 600 |
| ROOM_10007 | 13 | 640 | 360 |
| ROOM_10009 | 10 | 520 | 440 |
| ROOM_10012 | 25 | 740 | 590 |
| ROOM_10020 | 11 | 590 | 370 |
Active speakers and speech overlap statistics
The plots below compare the speech activity overlap and patterns between meeting set splits: Development meetings, Batch 1 and Batch 2 of Training meetings, and Evaluation meetings.
The following plot shows the number of active speakers in 3-second windows. The plot indicates there is a similar distribution of speech activity patterns across the meeting set splits. 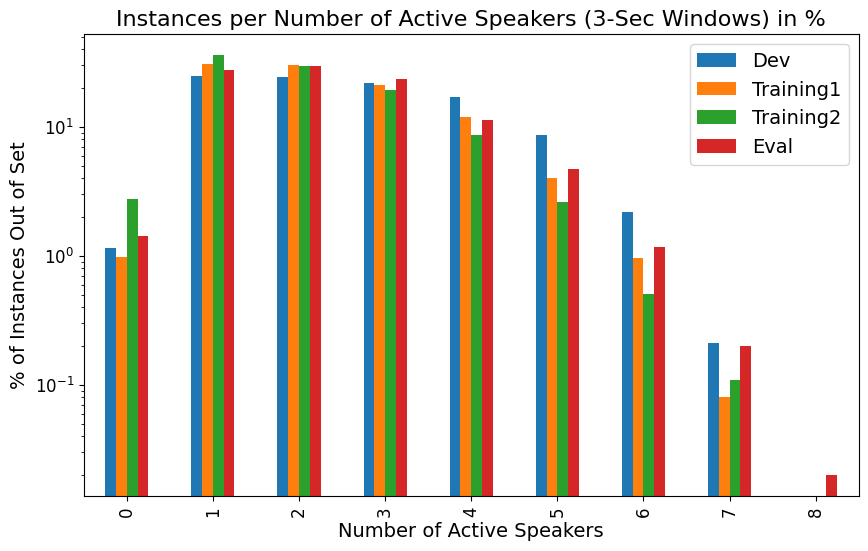
| active speakers | dev | training1 | training2 | eval | dev_percentage | training1_percentage | training2_percentage | eval_percentage |
|---|---|---|---|---|---|---|---|---|
| 0 | 304 | 265 | 2369 | 1199 | 1.15 | 0.98 | 2.76 | 1.42 |
| 1 | 6499 | 8278 | 30906 | 23352 | 24.65 | 30.77 | 36.04 | 27.65 |
| 2 | 6378 | 8133 | 25591 | 25156 | 24.19 | 30.23 | 29.84 | 29.79 |
| 3 | 5804 | 5660 | 16642 | 20024 | 22.01 | 21.04 | 19.4 | 23.71 |
| 4 | 4463 | 3205 | 7456 | 9580 | 16.93 | 11.91 | 8.69 | 11.34 |
| 5 | 2287 | 1087 | 2268 | 3957 | 8.67 | 4.04 | 2.64 | 4.69 |
| 6 | 576 | 257 | 441 | 996 | 2.18 | 0.96 | 0.51 | 1.18 |
| 7 | 55 | 21 | 91 | 166 | 0.21 | 0.08 | 0.11 | 0.2 |
| 8 | 0 | 0 | 1 | 15 | 0.0 | 0.0 | 0.0 | 0.02 |
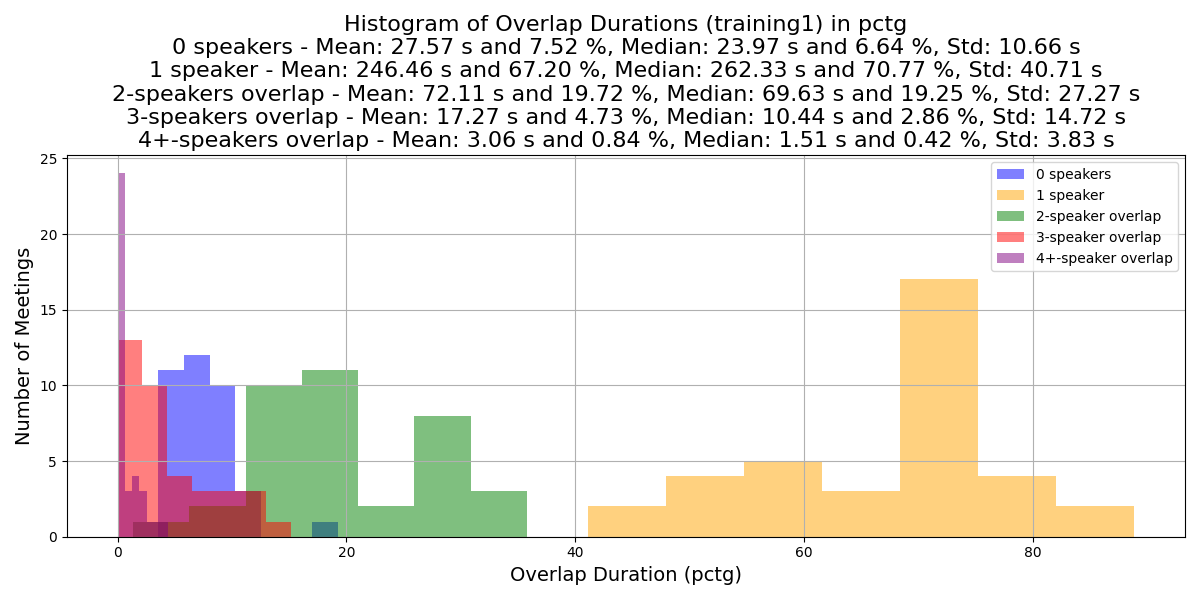
The following plots compare the distribution of speech overlaps across meeting set splits. 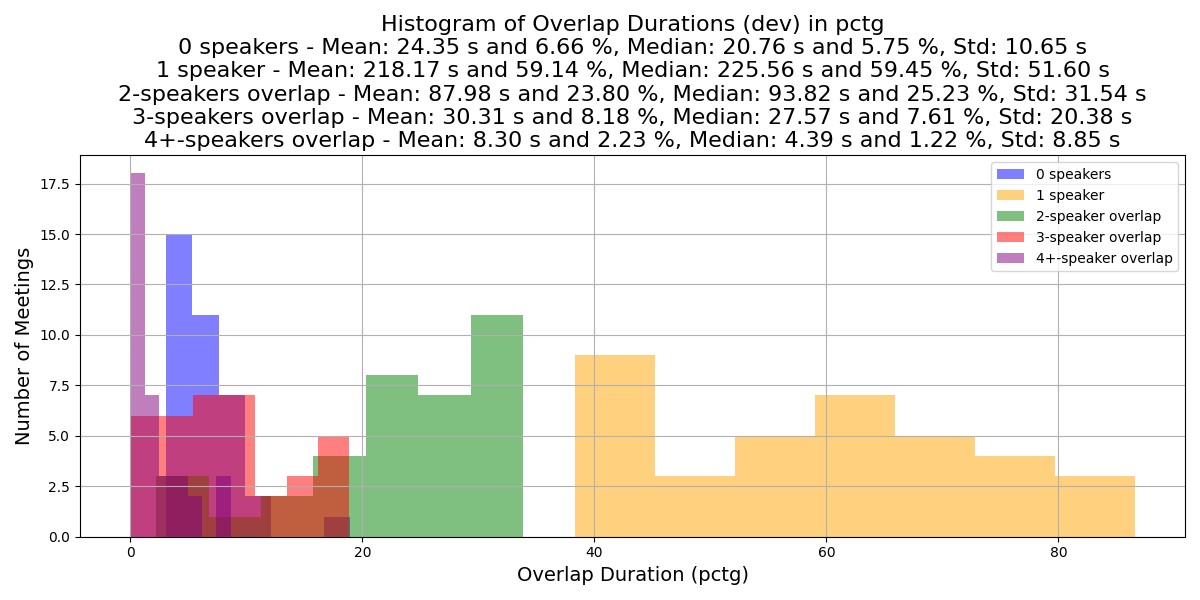
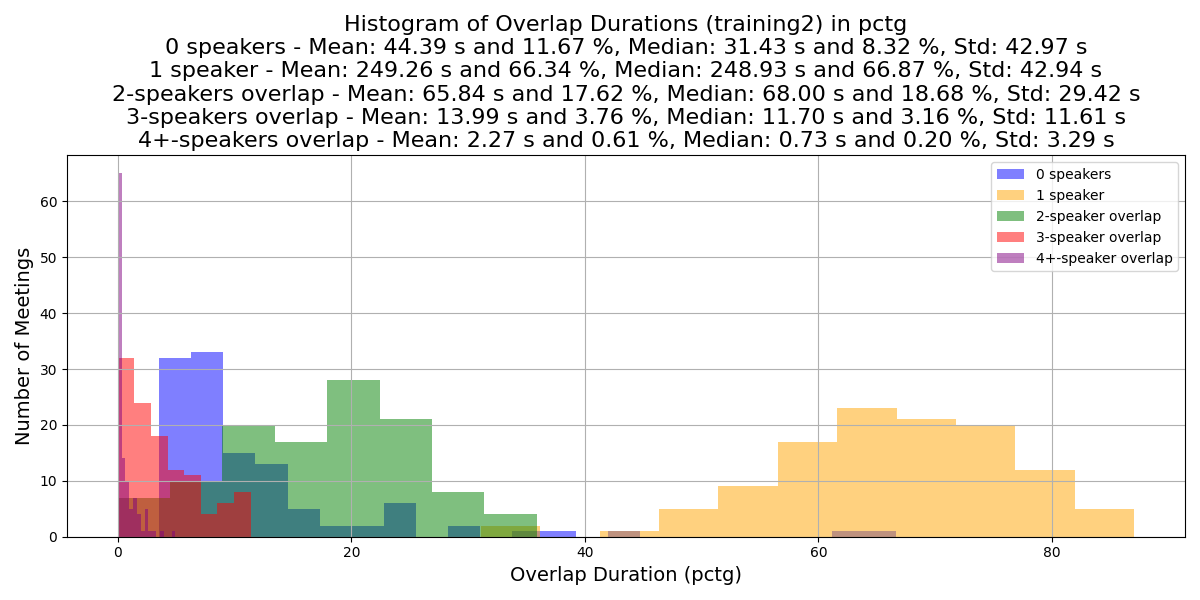
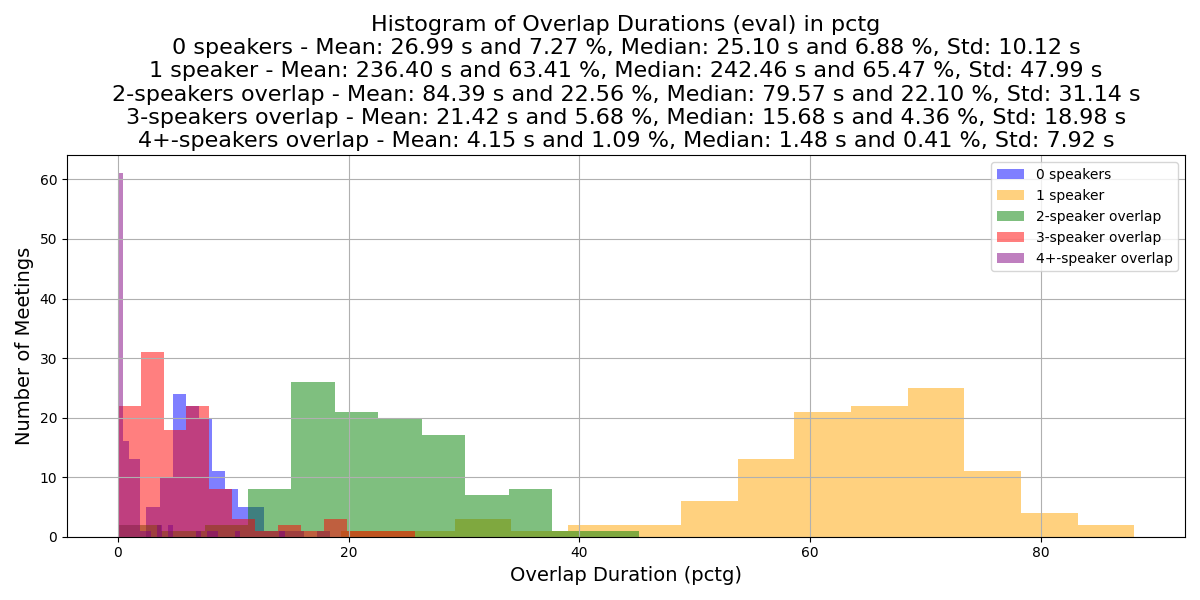
Simulated training dataset
The simulated training dataset consists of about 1000 hours simulated with the same microphone-array geometry as the multi-channel devices in the NOTSOFAR meeting dataset.
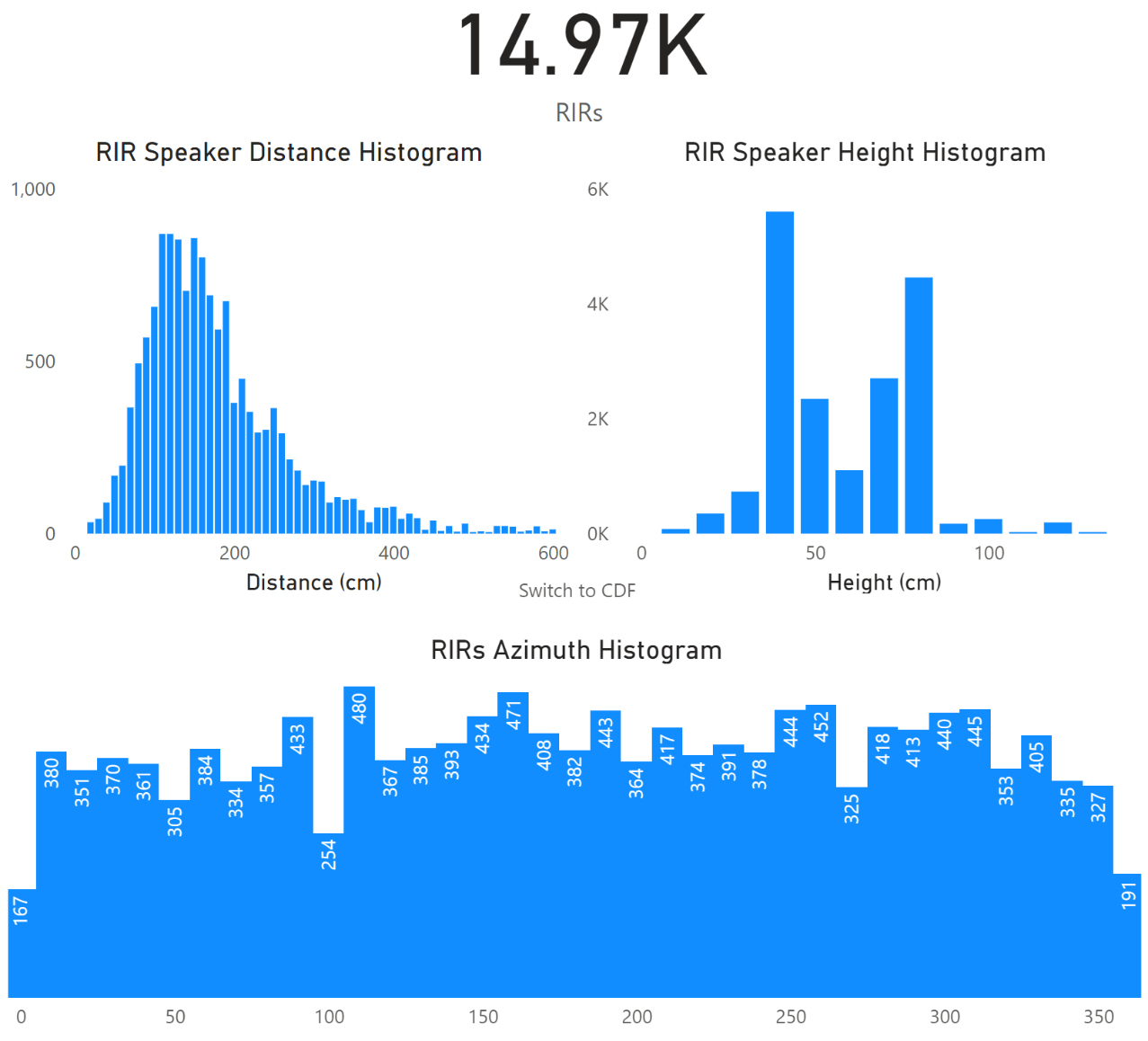
Real-room acoustic transfer functions (ATFs)
The dataset features ATFs recorded in actual conference rooms, in an acoustic setup arranged to closely replicate authentic meeting environments. We collected a total of 15,000 real ATFs, measured in various positions and rooms by multiple devices sharing the same geometry.
The ATFs were reconstructed from chirps emitted by a mouth simulator speaker. The histograms below show the distribution of mouth speaker locations relative to the microphone array.
Mixtures of up to three speakers
The simulated dataset provides speech mixtures along with their separated speech and noise components, which serve as supervision signals for training speech separation and enhancement models.
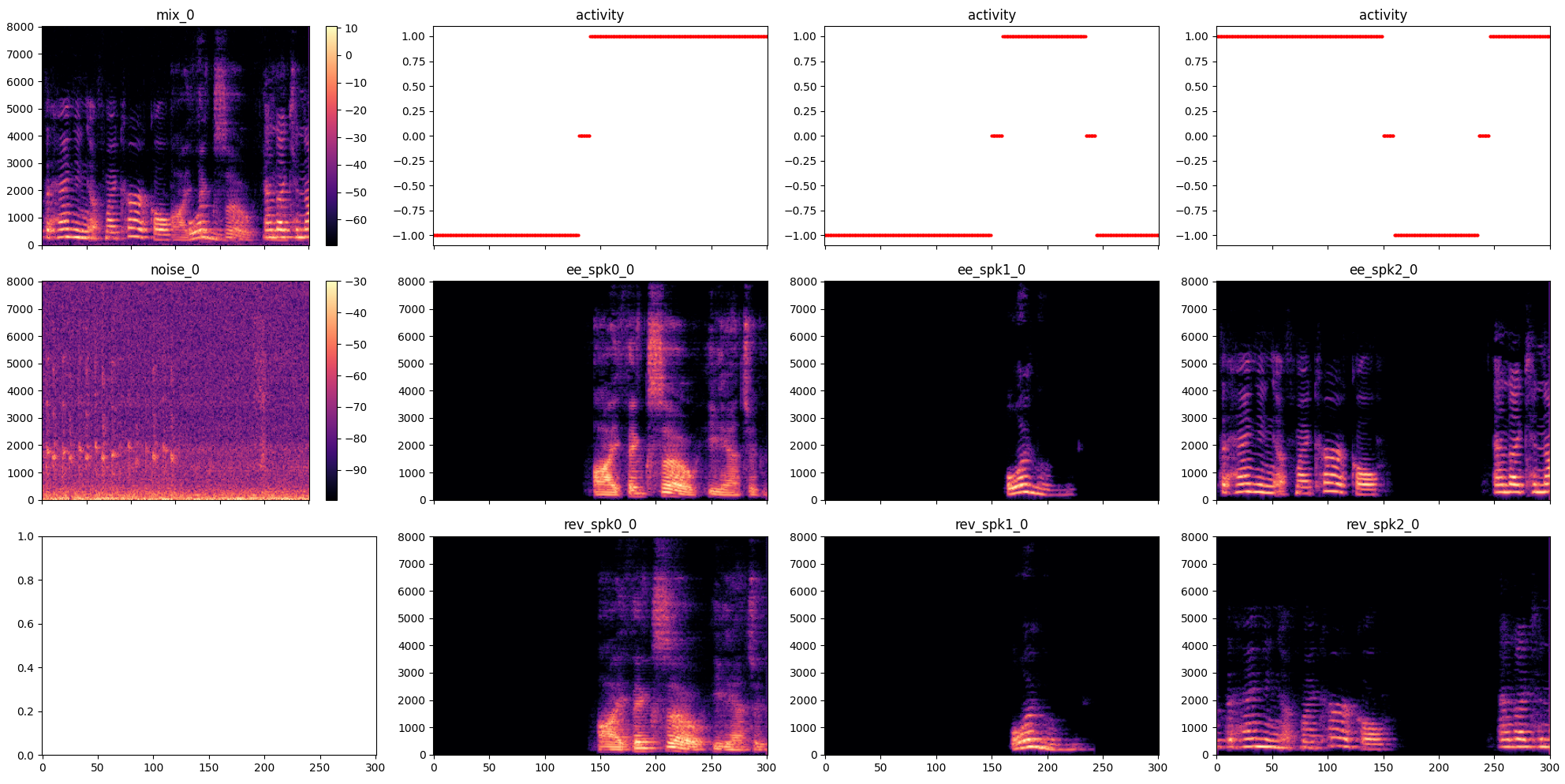
The plots below show examples of simulated audio mixtures and their isolated components. Each plot shows a 3 second segment of mixed speech of two or three speakers and noise. The X-axis units are 10-millisecond frames.
- mix_0 The mixture signal.
- activity The ground truth (GT) speech activity scores for each speaker. Values:
- -1: Not speaking.
- 0: Borderline energy. Represents a transition region between speech and silence.
- 1: Speaking.
- ee_spk0_0, ee_spk1_0 The direct path and early echoes component for each speaker.
- rev_spk0_0, rev_spk1_0 The reverberation component for each speaker.
- noise_0 The noise component of the segment.
The GT (ground truth) components sum up to the mixture:
mixture = gt_spk_direct_early_echoes + gt_spk_reverb + gt_noise
Simulated mixture example 1: Rapid speaker turns between two speakers
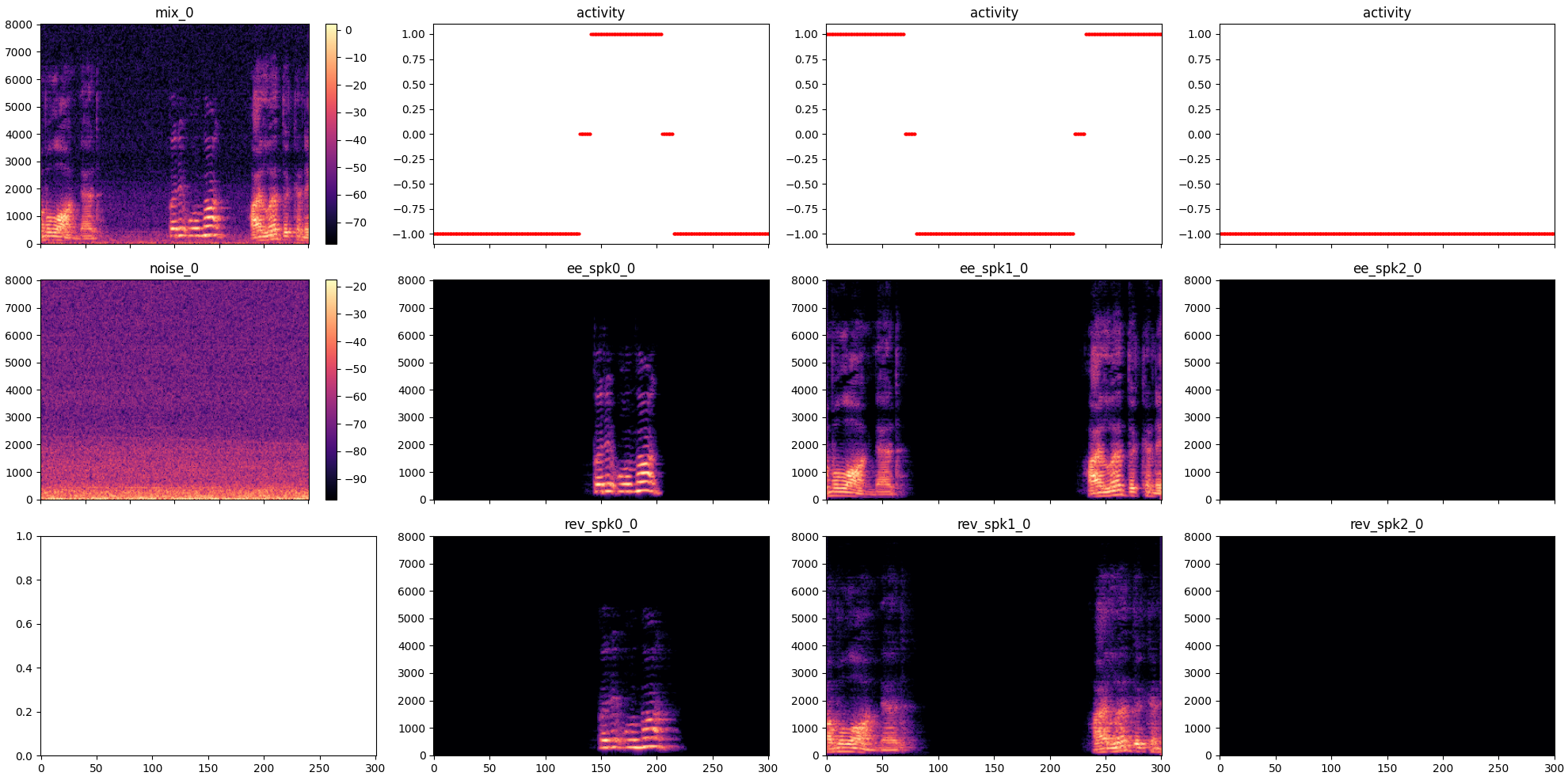
Simulated mixture example 2: Three speakers with speech overlaps
License
This public data is currently licensed for use exclusively in the NOTSOFAR challenge event. We appreciate your understanding that it is not yet available for academic or commercial use. However, we are actively working towards expanding its availability for these purposes. We anticipate a forthcoming announcement that will enable broader and more impactful use of this data. Stay tuned for updates. Thank you for your interest and patience.