CHiME-8 Task 1 - DASR
Distant Automatic Speech Recognition with Multiple Devices in Diverse Scenarios.

![]()
This task focuses on distant automatic speech transcription and diarization of meetings with a strong focus on generalization across many scenarios.
The goal of each participant is to devise an automated system that is able to generalize across:
- array topologies and, more broadly, recording setups.
- acoustic scenarios: office meetings, dinner parties and interviews.
- high variability in the number of speakers in the whole conversation (from 2 to up to 8 max speakers this year).
- high variability in the duration: from few minutes to hours.
- language style variations e.g. more formal or more colloquial.
To tackle this difficult problem, participants can exploit commonly used open-source datasets (e.g. AMI, LibriSpeech) and pre-trained models, including popular self-supervised models (WavLM, Wav2Vec 2.0 etc.) and, in a separate ranking, also large language models (LLMs).
Important Dates and Events
Have a look at Important Dates page.
Participants can propose additional external datasets and models including LLMs till 20th of March (AoE).
CHiME-2024 Interspeech Satellite Workshop
All participants are invited to present their work at the next CHiME-2024 Workshop.
- We strongly encourage in-person participation, but can make exceptions for teams that are unable to participate due to unexpected reasons. But if you are unable to participate in-person please email samuele.cornell@ieee.org.
- Participants will present their work in a poster session. Additionally, Organizers will choose a single team for oral presentation.
Participants are also encouraged to submit a full-paper (up to 6 pages, references included) after the workshop which will appear in the workshop proceedings.
The proceedings are included in the ISCA archive and will be registered (ISBN) and indexed by Thomson-Reuters and Elsevier.
We will also have a Computer Speech and Language Special Issue closely tied to this Challenge, which you can consider for further extension and analysis work.
📌 Registration
To participate, register using this Google Form (one form per team only).
📩 Contact Us/Stay Tuned
If you are considering participating or just want to learn more then please join the CHiME Google Group.
We have also a CHiME Slack Workspace, you can join the chime-8-dasr channel there or contact us organizers directly.
Challenge Short Description and Tracks
This Task has two tracks which differ only by the type of external language models (LM) allowed.
- Constrained LMs Track
- no pre-trained LMs allowed, teams can however develop whatever LM using core data and external_data.
- Unconstrained LMs Track
- teams can also leverage pre-trained LMs from this list (LLMs included).
👉 note that an entry to the constrained track is also valid for the unconstrained one but not vice-versa.
In both tracks, participants need to develop a system that performs automatic speech recognition (ASR) and diarization of long form meetings.
I.e. an automated system that, given multichannel recordings of a meeting, is able to obtain reasonable segmentation (with time marks at the utterance level) and transcriptions for each speaker.
See Submission page for an example of the output transcription we expect.
Scenarios and Datasets
This task features 4 highly diverse core datasets/scenarios on which performance will be evaluated:
| Scenario | Setting | Num. Speakers | Recording Setup | Multi-Room | Meeting Duration |
|---|---|---|---|---|---|
| CHiME-6 | dinner party | 4 | 6 linear arrays (4 mics each) | Yes | > 2h |
| DiPCo | dinner party (more formal) | 4 | 5 circular arrays (7 mics each) | No | 20-30 mins |
| Mixer 6 Speech | 1-to-1 interview | 2 | 10 heterogeneous devices | No | ~15 mins |
| NOTSOFAR1 | office meeting | 4-8 | 1 circular array device (7 mics) | No | ~6 mins |
For training, you can also use data from these but also from allowed open-source datasets.
For more information have a look at the Data page.
📊 Systems Ranking
In both tracks systems will be ranked according to scenario-wise macro time-constrained minimum permutation WER (tcpWER) with a collar of 5 s.
I.e. tcpWER is firstly computed on each scenario evaluation set separately and then averaged across the 4 scenarios.
🥇 In parallel, we will also feature a special award for one team selected by a jury.
The jury will be composed of experts nominated by the CHIME Steering Committee.
This selection will be based on (in order of importance):
- practicality/efficiency
- novelty
- effectiveness
For more information have a look at the Submission page.
Rules
Participants systems must:
- be unique across the 4 scenarios, you cannot do domain identification. -
- perform inference for each meeting/session independently (this applies also to any self-training adaptation technique).
Have a look at the complete Rules page. We also have a rules FAQs section.
DASR and NOTSOFAR1 Tasks
This year CHiME-8 will feature two closely related tasks: DASR (this one) and NOTSOFAR1.
While we focus on generalizability across many domains, the NOTSOFAR1 task focuses on the particular domain of short office meetings.
In DASR we make use of the same NOTSOFAR1 Task data, here however is treated as one of the scenarios among the total 4 ones.
The overall goal is to compare the submissions between these two tasks and see how a generalizable transcription system (as required in DASR) compares to a specialized transcription system for the particular NOTSOFAR-1 scenario.
We want to encourage participants to enroll in both tasks:
- what is the best way to adapt a generalist system (as in DASR task) to the particular short office meetings in NOTSOFAR-1 task ?
- how much performance can be boosted by adapting/fine-tuning on only one domain ?
- as a trade-off, how much performance will be lost in the other scenarios featured in DASR after such adaptation ?
🛠️ Baseline and Tools
⚡ Data Generation and Scoring
We offer an easy-to-use toolkit for downloading and preparing the core data: chime-utils.
It supports:
- CHiME-8 core datasets preparation, with automatic downloading for CHiME-6, DiPCo and NOTSOFAR1 data.
- Manifests preparation for many popular speech toolkits
- Kaldi and ESPNet
- K2/Icefall/Lhotse
- Official Scoring scripts
and more utilities to help a bit in handling this arduous challenge !
🚀 Baseline System
This year baseline system is built with NeMo.
It is based on the last year CHiME-7 DASR NeMo team submission and consists of:
- dereverberation+channel clustering,
- multichannel diarization based on multi-scale diarization decoder (MSDD),
- guided source separation and a fine-tuned Conformer RNN-T ASR model.
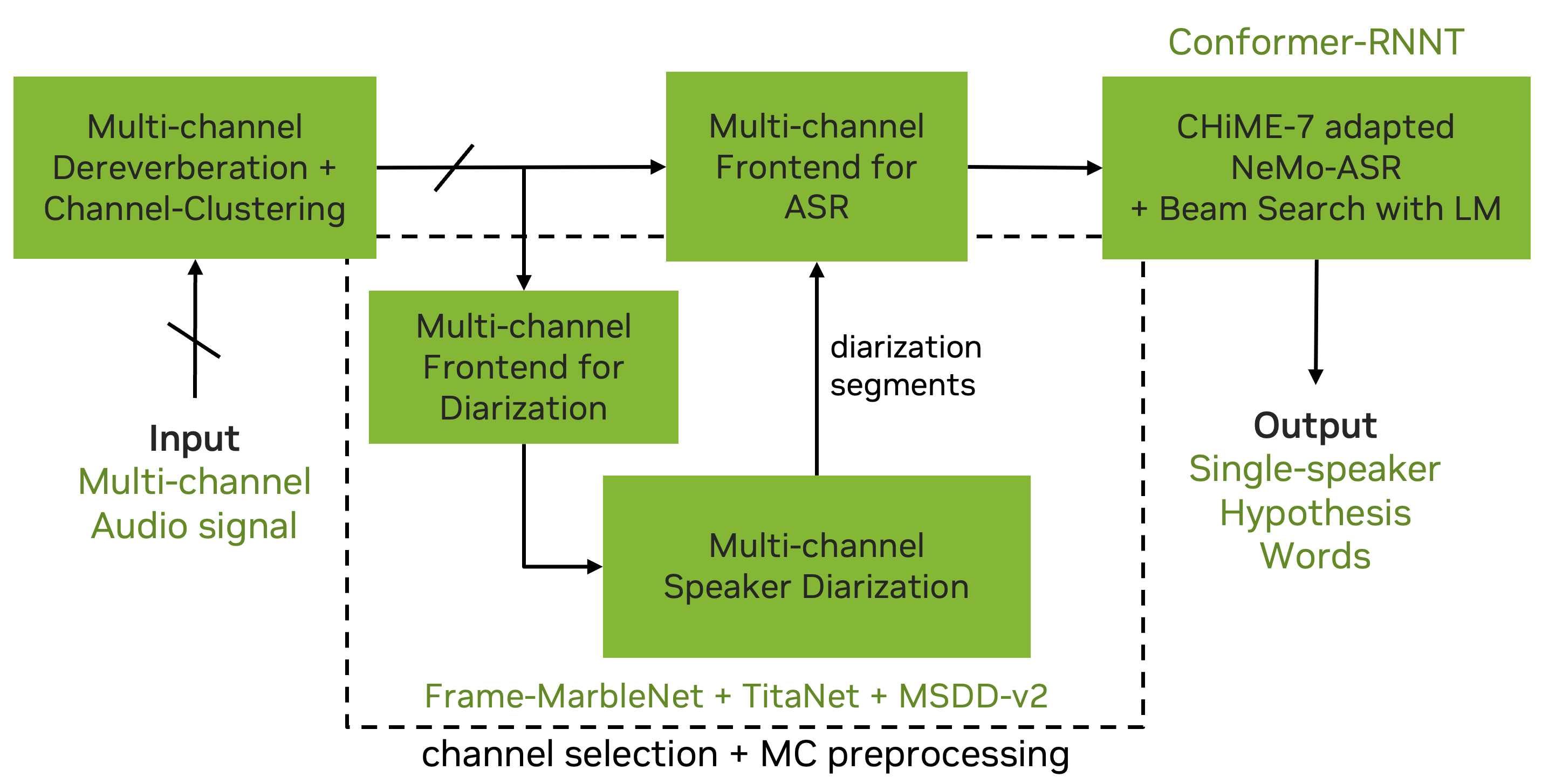
For more information have a look at the Baseline page.
What's new from CHiME-7 DASR ?
- An additional scenario from NOTSOFAR-1 Task, featuring short office meetings with up to 8 participants. This addition alone makes this Task much more challenging.
- No oracle diarization track. Two tracks that require joint ASR+diarization (both same as last year main track).
- The difference is that in one we allow the use of external large language models.
- At the same time, we want to encourage research towards practical solutions.
- There will be a special CHiME-8 Committee award mention for the most practical and innovative system. See Submission page.
- Manually corrected Mixer 6 Speech development set.
- An interactive Leaderboard for all the scenarios dev set (See Submission), together with NOTSOFAR-1 Task.
- DiPCo and Mixer 6 have now a training/adaptation portion.