Submission
![]()
- Please Register here.
- Evaluation data release dates is in Important Dates.
- NOTSOFAR1 development set ground truth annotation has been released see news in main page.
- For evaluation, ensure that your system is able to perform inference on an amount of data of ~30 hours in two weeks.
- We can offer some flexibility for unexpected problems but try to be on time ! (e.g. keep the system light and fast enough).
- At the challenge end, along with system predictions you will need also to submit a technical description paper of up to 4 pages + 1 for references (it can be shorter).
- You will get feedback from reviewers (see Important Dates) for this technical description paper.
- Results will be released the same day technical description papers feedback is released.
- Every participant is invited to present their work at the CHiME-8 Interspeech Satellite Workshop.
- 🥇 The jury award for the most practical and efficient system will be announced there.
- We strongly encourage in-person participation, but can make exceptions for teams that are unable to participate due to unexpected reasons.
- If you are unable to participate in-person please email samuele.cornell@ieee.org.
- Presentation format is poster session. Additionally, Organizers will choose a single team for oral presentation.
- After the Workshop participants are invited to submit a full-length paper (up to 6 pages, including references) which will appear in the Workshop proceedings and will be indexed.
- More info on publications is in the Main page.
🥷 If you want to still submit the final system but want to keep the final submission (and required technical description !) anonymous please email samuele.cornell@ieee.org directly.
📬 Where to Submit for Final Evaluation ?
You need to submit your predictions for both eval and dev sets using this Google Form.
Please submit all your systems (you can submit up to 4 per track) all once following the instructions hereafter.
📝 What do I need to submit for final evaluation ?
Participants have to submit the predictions of up to 4 systems (of course you can submit also less) for each track they choose to participate and a technical description paper.
If you participate to both tracks you can submit a single technical description paper covering both.
👉 If you participate only in the constrained LM track only, in that case your submission will also be valid for the unconstrained LM track (but, of course, it may perform worse than systems that leveraged LLMs).
👫 In the submission form we will ask for your system predictions for both evaluation and development sets.
💡 Our suggestion (it is not mandatory), is that you submit 4 systems:
- 2 systems tuned for the best performance (e.g. use ensembles and so on).
- another 2 systems where you try to win the jury award with more careful balance between runtime/efficiency and performance.
System Info YAML File
We also kindly ask (not mandatory) to include in the final submission for each system this YAML file containing basic information for each system about training & inference resources.
System Predictions Submission Format
We expect each submission to each track to have the following structure (including a separate YAML file for each system).
Note that this is an example with only 2 systems, but you can submit up to 4.
.
├── sys1
│ ├── dev
│ │ ├── chime6.json
│ │ ├── dipco.json
│ │ ├── mixer6.json
│ │ └── notsofar1.json
│ ├── eval
│ │ ├── chime6.json
│ │ ├── dipco.json
│ │ ├── mixer6.json
│ │ └── notsofar1.json
│ └── info.yaml
└── sys2
├── dev
│ ├── chime6.json
│ ├── dipco.json
│ ├── mixer6.json
│ └── notsofar1.json
├── eval
│ ├── chime6.json
│ ├── dipco.json
│ ├── mixer6.json
│ └── notsofar1.json
└── info.yaml
Thus, two sub-folders, one for each system containing JSON files with the predictions and the system information YAML file.
Each JSON file is a CHiME-6 style Segment-wise Long-form Speech Transcription (SegLST), as already described in Data Page (and same as past CHiME-7 DASR challenge).
I.e. each JSON contains predictions for each scenario and contains a list of dictionaries (one for each utterance), each with following attributes:
{
"end_time": "11.370",
"start_time": "11.000",
"words": "So, um [noise]",
"speaker": "P03",
"session_id": "S05"
}
📑 Technical Description Paper
Participants have also to submit ONE (even if team submitted to both tracks) short technical description paper (up to 4 pages, + 1 for references, it can be shorter) containing a description of the system.
Submission should be made using:
This technical description paper will be used:
- To evaluate for eligibility for the jury award for “Most Practical and Efficient System”.
- To assess correctness of submission and compliance with rules.
Teams should provide relevant information in the technical report included with their final submission. The technical description should cover:
- details to reproduce the systems
- external datasets, data augmentation strategies and external models used
- inference and training runtime and hardware specifications.
For each submission we strongly encourage also to include the following YAML file for each individual system, with a different tag for each system.
The YAML file contains relevant information to fill up regarding the individual system (e.g. external datasets and models used as well as inference runtime).
Please, make sure that the system names used in the technical description match the ones specified in the corresponding YAML file system_tag entry.
🏆 Jury Award for "Most Practical and Efficient System"
This year we introduced a special jury award/mention to encourage the development of innovative and practical systems, moving away from performance-squeezing, brute-force approaches such as ensembling or iterative inference-time pseudo-labeling & retraining.
- As such we highly recommend submitting your system, even if you think it is not great in terms of performance, as it still stands a chance to win this jury award if it is practically and scientifically interesting.
- Of course, each team is free to not to focus on such award if their main focus is on performance instead (e.g. LLM integration).
For this award all submitted systems are considered, no matter their evaluation set performance.
The jury award will be assigned based on the technical description papers, which are up to 4 pages plus references and will be reviewed by a pool of experts. It will be determined based on the following criteria, in order of importance:
- practicality and efficiency
- novelty
- final results
As said, this award will be assigned based on reviews from a pool of experts.
They will use each team technical description paper as well as the submitted material, including the systems YAML file.
As an example we list hereafter some examples of challenge submissions that we think would have qualified for such jury award.
These works proposed effective and novel components with lasting impact on the field.
- Boeddeker, C., Heitkaemper, J., Schmalenstroeer, J., Drude, L., Heymann, J., & Haeb-Umbach, R. (2018, September). Front-end processing for the CHiME-5 dinner party scenario. In CHiME5 Workshop, Hyderabad, India (Vol. 1).
- Medennikov, I., Korenevsky, M., Prisyach, T., Khokhlov, Y., Korenevskaya, M., Sorokin, I., … & Romanenko, A. (2020). Target-Speaker Voice Activity Detection: a Novel Approach for Multi-Speaker Diarization in a Dinner Party Scenario.
- Erdogan, H., Hayashi, T., Hershey, J. R., Hori, T., Hori, C., Hsu, W. N., … & Watanabe, S. Multi-Channel Speech Recognition: LSTMs All the Way Through.
- Heymann, J., Drude, L., Chinaev, A., & Haeb-Umbach, R. (2015, December). BLSTM supported GEV beamformer front-end for the 3rd CHiME challenge. In 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU) (pp. 444-451). IEEE.
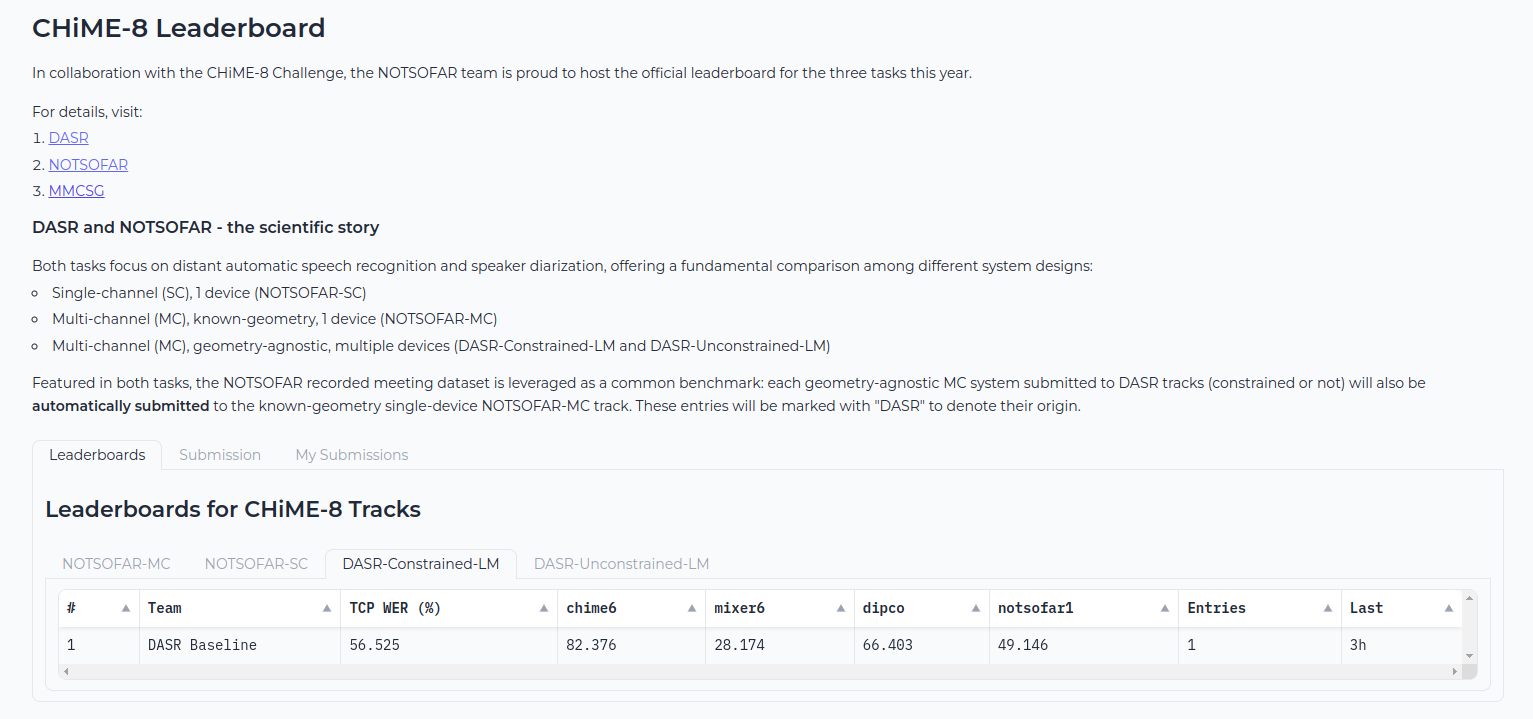
Interactive Leaderboard (Dev Set Only)
Leaderboard is now online and available at: https://huggingface.co/spaces/NOTSOFAR/CHiME8Challenge.
🥷 Anonynous submission is allowed on the leaderboard !
How to submit to the leaderboard ?
- You need first to create an Huggingface Hub 🤗 account: https://huggingface.co/docs/huggingface_hub/quick-start.
- Secondly, you need to create an access token: https://huggingface.co/docs/hub/security-tokens
Then you are ready to submit !
For each submission you will be asked:
- Team Name: The name of your team, as it will appear on the leaderboard’
- Results: Results zip file to submit
- Submission track: The track to submit results to
- Token: Your Hugging Face token
- Description: Short description of your submission (optional)
The results should be a zip file of a folder called “dev” with the following structure:
├── dev
│ ├── chime6.json
│ ├── dipco.json
│ ├── mixer6.json
│ └── notsofar1.json
Where each JSON file is a JSON SegLST already described in Data Page (and same as past CHiME-7 DASR challenge), it is also described in the bottom of this page.
We provide also an example submission for the baseline as it may be helpful: dev.zip.
📊 Ranking Score
In both tracks we will use scenario-wise macro time-constrained minimum permutation word error rate (tcpWER) with 5 s collar to rank the systems. tcpWER is firstly computed on each scenario evaluation set separately and then averaged across the 4 scenarios.
📏 We apply text normalization on both participants systems output and the ground truth before computing this score.
You can have a look at the normalized ground truth for each core dataset, it is in the transcriptions_scoring folder.
This year we use Whisper-style text normalization. However, it is modified to be idempotent and less “aggressive” (closer to the original text).
You can compute the ranking score e.g. on development set using chime-utils:
chime-utils score tcpwer -s /path/to/submission/folder -r /path/to/c8dasr_root --dset-part dev --ignore
--ignore flag is needed if you lack some ground truth (e.g. NOTSOFAR1 dev ground truth will not be released till the last month of the challenge).
The scoring will skip that scenario. You have to use the leaderboard for that one.
📩 Contact
For questions or help, you can reach the organizers via CHiME Google Group or via CHiME Slack Workspace.