Data
- Download and references
- Overview
- Audio
- Isolated: segmented noisy speech data
- Enhanced: enhanced speech data
- Backgrounds: background noises
- Embedded: unsegmented noisy speech data
- Annotations
- Transcriptions
- WSJ0
Download and references
The data are only distributed via the LDC as LDC2017S24.
To refer to these data in a publication, please cite:
- Jon Barker, Ricard Marxer, Emmanuel Vincent, and Shinji Watanabe
The third 'CHiME' Speech Separation and Recognition Challenge: Dataset, task and baselines
In Proc. IEEE 2015 Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 504-511, 2015. - Jon Barker, Ricard Marxer, Emmanuel Vincent, and Shinji Watanabe
The third 'CHIME' Speech Separation and Recognition Challenge: Analysis and outcomes
Computer Speech and Language, vol. 46, pp. 605-626, 2017.
Overview
The 3rd CHiME challenge sets a target for distant-talking automatic speech recognition using a read speech corpus. We use a similar setup as the 2013 CHiME Challenge Track 2 based on the speaker-independent medium (5k) vocabulary subset of the Wall Street Journal (WSJ0) corpus, and we also provide baseline software including data simulation, speech enhancement, and ASR. The ASR baseline uses the Kaldi ASR toolkit. Two types of data are employed: `Real data' -- speech data that is recorded in real noisy environments (on a bus, cafe, pedestrian area, and street junction) uttered by actual talkers. `Simulated data' - noisy utterances that have been generated by artificially mixing clean speech data with noisy backgrounds. The ultimate goal is to recognise the real data. Main audio data are provided as 16 bit stereo WAV files sampled at 16 kHz.
Training set: 1600 (real) + 7138 (simulated) = 8738 noisy utterances from a total of 4 speakers in the real data, and 83 speakers forming the WSJ0 SI-84 training set in the 4 noisy environments. The transcriptions are also based on those of the WSJ0 SI-84 training set, but the real speech utterances do not contain verbal punctuations (e.g., “period” and “hyphen” in the original WSJ0 SI-84). All of the reading errors in these transcriptions are corrected appropriately.
Development set: 410 (real) X 4 (environments) + 410 (simulated) X 4 (environments) = 3280 utterances from 4 other speakers than the speakers in the training data. The utterances are based on the “no verbal punctuation” (NVP) part of the WSJ0 speaker-independent 5k vocabulary development set.
Test set: 330 (real) X 4 (environments) + 330 (simulated) X 4 (environments) = 2640 utterances from 4 other speakers. Similarly to the development set, the utterances are based on the “no verbal punctuation” (NVP) part of the WSJ0 speaker-independent 5k vocabulary evaluation set.
Audio data, annotations, transcriptions, and a subset of the original WSJ0 dataset are provided based on the following directory structure:
├── annotations
├── audio
├── transcriptions
└── WSJ0
Audio
All audio data (real, simulated, and enhanced audio data) are distributed with a sampling rate of 16 kHz. The 3rd CHiME challenge baseline system including data simulation, speech enhancement, and ASR uses only the 16 kHz audio data. The audio data consists of the background noises (backgrounds), enhanced speech data using the baseline speech enhancement technique (enhanced), unsegmented noisy speech data (embedded), and segmented noisy speech data (isolated) based on the following data structure:
├── backgrounds
├── enhanced
├── embedded
└── isolated
Isolated: segmented noisy speech data
The segmented noisy speech data are composed of real (REAL), simulated (SIMU), and clean (ORG) speech data.- REAL: The real data are recorded with 5 locations, i.e., booth (BTH), on the bus (BUS), cafe (CAF), pedestrian area (PED), and street junction (STR). Among these, BUS, CAF, PED, and STR data are used as the main ASR evaluation, and BTH data are used to construct the simulated data. The subdirectory names of real BUS, CAF, PED, and STR data have a suffix "_real". The prefix of the subdirectory names (tr05, dt05, and et05) denotes the training, development, and evaluation sets. For instance, "dt05_bus_real" means the 5k-vocabulary development set of the real data recorded in the bus environment.
Some samples of the real (i.e. live-recorded) noisy speech data can be heard below.Click images below to hear samples

Cafe 
Street 
On the bus 
Pedestrian area - SIMU: The simulated data are also composed of 4 noisy locations (BUS, CAF, PED, and STR) excluding BTH, and follow the same pattern of subdirectory names as those of the real data. The baseline simulated data of the development set (and the evaluation set) are generated from the BTH recording data (i.e., dt05_bth), while those of the training set are generated from the original WSJ0 training data described below.
- ORG: The clean speech data are based on the original WSJ0 training data (si_tr_s, 7,138 utterances). These are used to generate the simulated data of the training set. These data are already converted from NIST SPHERE format (.wv1) to WAV format (.wav).
Real/Simu | Location | Channels | # speakers | # utterances | hour | # of WAV files | |
dt05_bth | BTH | 0-6 | 4 | 410 | 0.72 | 2870 | |
dt05_bus_real | REAL | BUS | 0-6 | 4 | 410 | 0.68 | 2870 |
dt05_bus_simu | SIMU | BUS | 1-6 | 4 | 410 | 0.72 | 2460 |
dt05_caf_real | REAL | CAF | 0-6 | 4 | 410 | 0.69 | 2870 |
dt05_caf_simu | SIMU | CAF | 1-6 | 4 | 410 | 0.72 | 2460 |
dt05_ped_real | REAL | PED | 0-6 | 4 | 410 | 0.67 | 2870 |
dt05_ped_simu | SIMU | PED | 1-6 | 4 | 410 | 0.72 | 2460 |
dt05_str_real | REAL | STR | 0-6 | 4 | 410 | 0.7 | 2870 |
dt05_str_simu | SIMU | STR | 1-6 | 4 | 410 | 0.72 | 2460 |
tr05_bth | BTH | 0-6 | 4 | 399 | 0.75 | 2793 | |
tr05_bus_real | REAL | BUS | 0-6 | 4 | 400 | 0.69 | 2800 |
tr05_bus_simu | SIMU | BUS | 1-6 | 83 | 1728 | 3.71 | 10368 |
tr05_caf_real | REAL | CAF | 0-6 | 4 | 400 | 0.76 | 2800 |
tr05_caf_simu | SIMU | CAF | 1-6 | 83 | 1794 | 3.77 | 10764 |
tr05_org | single | 83 | 7138 | 15.15 | 7138 | ||
tr05_ped_real | REAL | PED | 0-6 | 4 | 400 | 0.72 | 2800 |
tr05_ped_simu | SIMU | PED | 1-6 | 83 | 1765 | 3.75 | 10590 |
tr05_str_real | REAL | STR | 0-6 | 4 | 400 | 0.73 | 2800 |
tr05_str_simu | SIMU | STR | 1-6 | 83 | 1851 | 3.92 | 11106 |
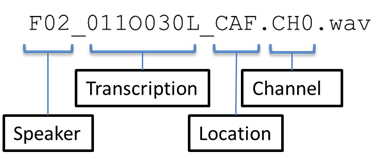
Note that the channel indexes 1 to 6 (*.CH[1-6].wav) specify the tablet microphones (see microphone positions in the tablet), and channel index 0 (*.CH0.wav) denotes the close talk microphone. The simulated data do not contain WAV files for the close talk microphone.
By following this naming convention, the converted WAV files from the original WSJ0 data are also renamed as follows:
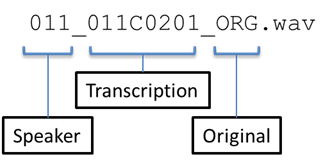
Note that the channel indexes of isolated clean speech WAV files are omitted.
Enhanced: enhanced speech data
The enhanced speech data are obtained from the baseline speech enhancement method. The subdirectory structure is almost the same except that it does not include booth and original clean speech data (dt05_bth, tr05_bth, and tr05_org). The naming convention is as follows: 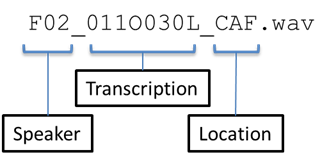
Real/Simu | Location | Channels | # speakers | # utterances | hour | # of WAV files | |
dt05_bus_real | REAL | BUS | single | 4 | 410 | 0.68 | 410 |
dt05_bus_simu | SIMU | BUS | single | 4 | 410 | 0.72 | 410 |
dt05_caf_real | REAL | CAF | single | 4 | 410 | 0.69 | 410 |
dt05_caf_simu | SIMU | CAF | single | 4 | 410 | 0.72 | 410 |
dt05_ped_real | REAL | PED | single | 4 | 410 | 0.67 | 410 |
dt05_ped_simu | SIMU | PED | single | 4 | 410 | 0.72 | 410 |
dt05_str_real | REAL | STR | single | 4 | 410 | 0.7 | 410 |
dt05_str_simu | SIMU | STR | single | 4 | 410 | 0.72 | 410 |
tr05_bus_real | REAL | BUS | single | 4 | 400 | 0.69 | 400 |
tr05_bus_simu | SIMU | BUS | single | 83 | 1728 | 3.71 | 1728 |
tr05_caf_real | REAL | CAF | single | 4 | 400 | 0.76 | 400 |
tr05_caf_simu | SIMU | CAF | single | 83 | 1794 | 3.77 | 1794 |
tr05_ped_real | REAL | PED | single | 4 | 400 | 0.72 | 400 |
tr05_ped_simu | SIMU | PED | single | 83 | 1765 | 3.75 | 1765 |
tr05_str_real | REAL | STR | single | 4 | 400 | 0.73 | 400 |
tr05_str_simu | SIMU | STR | single | 83 | 1851 | 3.92 | 1851 |
Note that the directory assumes that the enhanced speech data are single channel WAV files, and the channel information is not included in the file name. If you use your own speech enhancement technique, and evaluate it with the provided ASR tool, you should retain the exactly same directory structure and audio file names with this enhanced directory, and only change the directory name.
Backgrounds: background noises
Background noises were also recorded using the same tablet device at the same noisy locations (BUS, CAF, PED, and STR). These noises are employed to create simulated data matched with the real noisy speech data. Since these were recorded without speech, these do not include close-talk microphone signals (*.CH0.wav). All background noises are stored in CHiME3/data/audio/16kHz/backgrounds without using subdirectories. The naming convention is as follows:
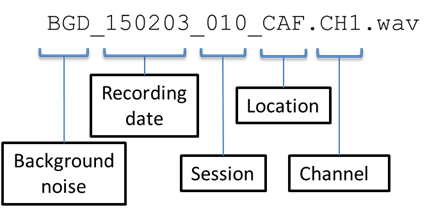
Real/Simu | Location | Channels | # sessions | hour | # of WAV files | |
backgrounds | REAL | BUS/CAF/PED/STR | 1-6 | 17 | 8.42 | 102 |
Embedded: unsegmented noisy speech data
The unsegmented noisy speech data (embedded) are originally recorded data, and the segmented noisy speech data (isolated) are obtained by segmenting these embedded data into separate utterances. The segmentation information can be found in the JSON files in CHiME3/data/annotations/, which is explained in the annotation section below. All embedded data are stored in CHiME3/data/audio/16kHz/embedded without using subdirectories. The naming convention is as follows:
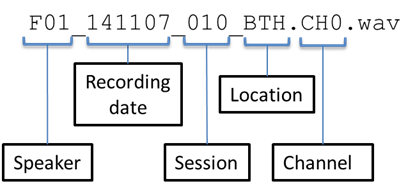
Real/Simu | Location | Channels | # speakers | # sessions | hour | # of WAV files | |
embedded | REAL | BUS/CAF/PED/STR | 0-6 | 8 | 51 | 13.98 | 357 |
Annotations
Annotation files in the CHiME3 data are based on the JSON (JavaScript Object Notation) format (see http://json.org/ in more detail). We prepared 7 JSON annotation files that contain all information needed for data simulation, speech enhancement, and ASR experiments.Note that, in the case when the speaker repeated a sentence several times, only one instance was retained and annotated, but the other instances were not removed from the embedded recordings.
CHiME3/data/annotations/dt05_real.json
The JSON files contain the various annotations for every utterance. Real utterances have the following 8 basic fields:
{
"dot": "Chrysler reduced some prices on Friday",
"end": 35.51843750000000,
"environment": "BUS",
"prompt": "Chrysler reduced some prices on Friday.",
"speaker": "M03",
"start": 32.53018750000000,
"wavfile": "M03_141106_040_BUS",
"wsj_name": "050C010A"
},
- "dot": transcription. When the speaker wrongly uttered the sentence, it was appropriately corrected (thus, "prompt" and "dot" differ sometimes).
- "end": end point time (second) of the embedded (unsegmented) noisy speech data. This is used to segment the embedded data to provide the isolated (segmented) noisy speech data with the start point time.
- "environment": noisy environment.
- "prompt": actual prompt shown in the tablet display for speakers to read a sentence.
- "speaker": speaker id.
- "start": start point time (second) of the embedded (unsegmented) noisy speech data. This is used to segment the embedded data to provide the isolated (segmented) noisy speech data with the end point time.
- "wavfile": WAV file id.
- "wsj_name": corresponding WSJ0 utterance id.
CHiME3/data/annotations/dt05_simu.json
In addition to the above basic fields, the JSON file for the simulated development set has some additional fields:
{
"dot": "Chrysler reduced some prices on Friday",
"end": 45.08006250000000,
"environment": "BUS",
"noise_end": 35.48262500000000,
"noise_start": 32.56600000000000,
"noise_wavfile": "M03_141106_040_BUS",
"prompt": "Chrysler reduced some prices on Friday.",
"speaker": "M03",
"start": 42.16343750000000,
"wavfile": "M03_141106_010_BTH",
"wsj_name": "050C010A"
},
- "noise_end": end point time (second) of the background noise data. This is used to extract a noise segment to create the simulated noisy speech data with the start point time of the background noise data.
- "noise_start": start point time (second) of the background noise data.
- "noise_wavfile": background noise data (WAV file) used to generate the simulated noisy speech data.
CHiME3/data/annotations/tr05_simu.json
Similarly, the JSON file for the simulated training set has some additional fields:
{
"dot": "I always wanted to work on the inside in",
"environment": "PED",
"ir_end": 424.3202500000000,
"ir_start": 420.8561875000000,
"ir_wavfile": "F02_141106_050_PED",
"noise_end": 1150.329625000000,
"noise_start": 1146.872312500000,
"noise_wavfile": "BGD_150203_010_PED",
"prompt": "I always wanted to work on the inside in.\"",
"speaker": "011",
"wsj_name": "011C0207"
},
- "ir_end": end point time (second) of the embedded speech file from which the impulse response was estimated. This impulse response is then used to filter original WSJ0 clean speech.
- "ir_start": start point time (second) of the embedded speech file from which the impulse response was estimated.
- "ir_wavfile": embedded speech file (WAV file) from which the impulse response was estimated.
Transcriptions
There are two types of transcription formats:- DOT format: it is used in the original WSJ0 corpus, and forms a standard sentence with the utterance ID at the end.
ex) That's another story (F01_051C0104_BUS) - TRN format: it is obtained from the DOT format with some text normalization process (CHiME3/tools/ASR/local/normalize_transcript.pl) used in the Kaldi WSJ recipe. All letters are capital, and the utterance id is at the beginning.
ex) F01_051C0104_BUS THAT'S ANOTHER STORY
The transcription directory has similar subdirectory structure to that of the segmented noisy speech data (isolated, CHiME3/data/audio/16kHz/isolated). The naming convention also follows that of the segmented noisy speech data except that the transcription file does not have the information of the channel, i.e.,
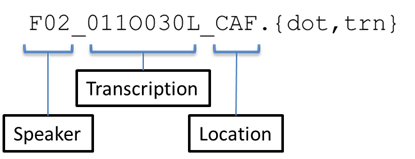
In CHiME3/data/transcriptions, there are also *.dot_all and *.trn_all files that contain a set of DOT and TRN transcriptions, where each line corresponds to a DOT/TRN transcription. The dot_all/trn_all files and the dot/trn files in the subdirectories carry the same information.