Baseline System
Overview
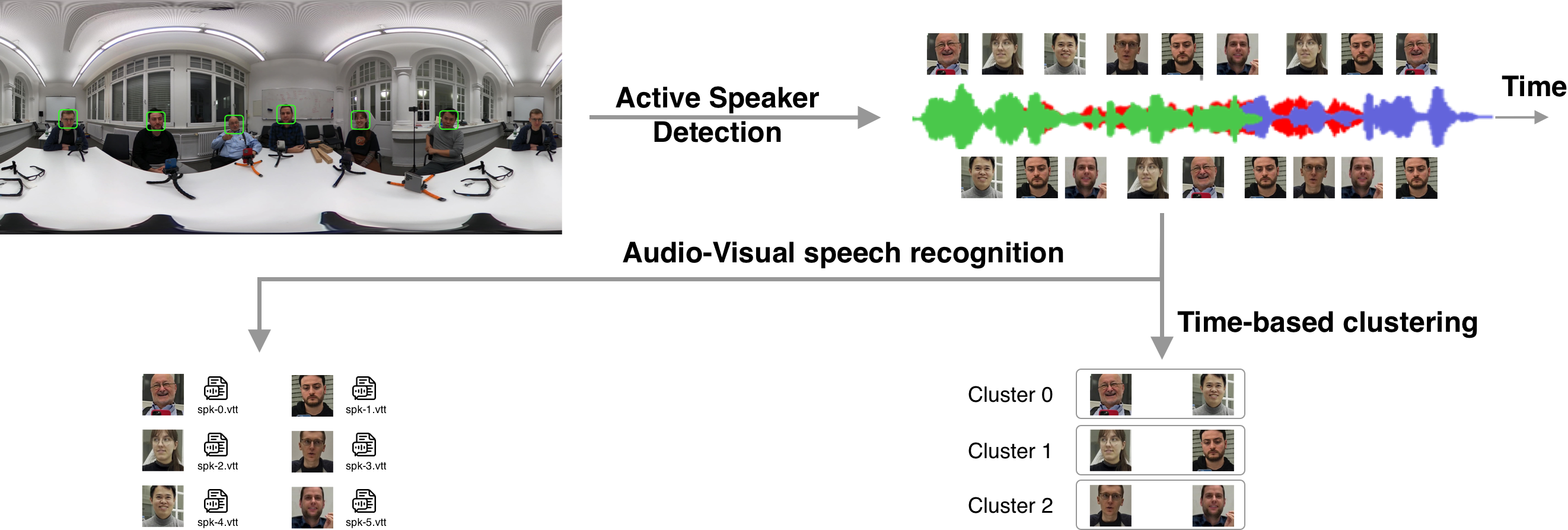
The baseline system for CHiME-9 Task 1 addresses the challenging problem of Multi-Modal Context-aware Recognition (MCoRec) in single-room environments with multiple concurrent conversations. The system processes 360° video and audio recordings to both transcribe each speaker’s speech and identify which speakers belong to the same conversation.
Task Requirements
The baseline system provides an initial framework for addressing two interconnected challenges:
- Individual Speaker Transcription: Generate time-aligned transcripts (
.vttfiles) for each target speaker within specified evaluation intervals - Conversation Clustering: Group participants into their respective conversations by generating speaker-to-cluster mappings
Input: Single 360° video with audio, plus bounding boxes identifying target participants Output: Per-speaker transcriptions and conversation cluster assignments
Baseline System Architecture
The baseline system is provided at Github. Please refer to the README therein for information about how to install and run the system.
Core Components
1. Active Speaker Detection
- Purpose: Determines which speaker is actively speaking at any given moment
- Baseline Model: A Light Weight Model for Active Speaker Detection
- Input: Face crop video and audio extracted from the 360° video
- Output: Active speaker detection scores for each frame of the corresponding track video. These scores are used to determine when a speaker is talking, allowing the audio-visual speech recognition system to run only during the speaking segments.
2. Face Landmark Detection and Mouth Cropping
- Purpose: Extracts mouth region from face crop videos.
- Models:
- Face detector based on RetinaFace
- 2D facial landmark detector based on FAN (Face Alignment Network)
- Input: Face crop video and audio extracted from the 360° video
- Output: Mouth crop video with precise mouth region extraction
- Processing Pipeline: Referenced from Auto-AVSR/preparation repository
3. Video Segmentation and Chunking
- Purpose: Splits long mouth crop videos into smaller segments (≤15 seconds) based on active speaker detection scores for efficient processing
- Algorithm:
- Hysteresis Thresholding: Uses onset and offset thresholds to identify speech regions from ASD scores
- Duration Filtering: Removes short speech segments and fills short gaps between speech regions
- Segment Splitting: Divides long continuous speech regions into manageable chunks
- Input: Mouth crop video and active speaker detection scores
- Output: List of video segments with start/end timestamps
4. Audio-Visual Speech Recognition
- Purpose: Combines audio and visual cues to transcribe speech into text for each video segment
- Input: Segmented mouth crop videos with corresponding audio streams and timestamps
- Output: Time-aligned transcriptions in WebVTT format with start/end timestamps for each segment
- Baseline Model
5. Time-based Conversation Clustering
- Purpose: Groups speakers into their respective conversations based on temporal speaking patterns and overlap analysis
- Input: Active speaker detection scores
- Processing Workflow:
- Speaker Activity Extraction: Uses ASD scores from the Active Speaker Detection component to identify time segments where each speaker is actively talking
- Conversation Score Calculation: For each pair of speakers, computes interaction scores based on temporal overlap patterns:
- Simultaneous speech (overlap) → indicates different conversations
- Sequential speech (non-overlap) → indicates same conversation
- Score formula:
1 - (overlap_duration / total_duration)
- Distance Matrix Construction: Converts conversation scores to distances for clustering:
- Higher scores (less overlap) = smaller distances = higher probability of same conversation
- Lower scores (more overlap) = larger distances = lower probability of same conversation
- Agglomerative Clustering: Hierarchically groups speakers using the distance matrix
- Output: Speaker-to-cluster mapping in JSON format (
speaker_to_cluster.json)
This baseline establishes a reference implementation that participants can build upon and improve through more sophisticated approaches to better handle the challenging multi-conversation scenarios with high speech overlap and complex acoustic environments.
Results
The results for the baseline systems on dev subset are the following:
| System | AVSR Model | MCoRec finetuned | Conversation Clustering | Conversation Clustering F1 Score | Speaker WER | Joint ASR-Clustering Error Rate |
|---|---|---|---|---|---|---|
| BL1 | AV-HuBERT CTC/Attention | No | Time-based | 0.8153 | 0.5536 | 0.3821 |
| BL2 | Muavic-EN | No | Time-based | 0.8153 | 0.7180 | 0.4643 |
| BL3 | Auto-AVSR | No | Time-based | 0.8153 | 0.8315 | 0.5211 |
| BL4 | AV-HuBERT CTC/Attention | Yes | Time-based | 0.8153 | 0.4990 | 0.3548 |
For detailed implementation and inference instructions, please refer to the baseline repository on GitHub.