Introduction
Separating and recognising speech in everyday listening conditions
One of the chief difficulties of building distant-microphone speech recognition systems for use in `everyday' applications, is that we live our everyday lives in acoustically cluttered environments. A speech recognition system designed to operate in a family home, for example, must contend with competing noise from televisions and radios, children playing, vacuum cleaners, outdoors noises from open windows — an array of sound sources of enormous variation. Such domains may be complex and seemingly unpredictable but nevertheless contain structure that can be learnt and exploited given enough data.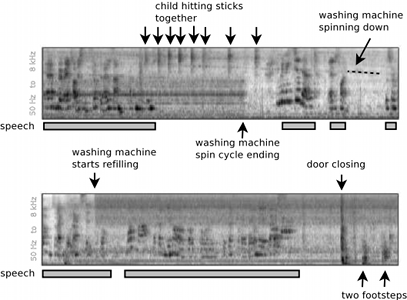 The figure to the right shows a time-frequency representation of a twenty second segment of domestic living room data that forms the background for the PASCAL 'CHiME' challenge. The figure illustrates some of the huge challenges presented by the target scenario: there is a noise floor that, although quasi-stationary, can change abruptly in response to unpredictable changes of state in the room (doors opening, appliances being turned on or off); on top of the background there are abrupt impact noises such as footsteps and doors banging that can mask even highly energetic portions of the speech signal; there may be multiple speakers in the room producing overlapping speech; the positions of the competing sound sources can change over time, etc, etc. There are many partial solutions to the problem of noise-robust ASR: systems either attempt to filter out the noise, directly model the combination of the noise and the speech or use signal-level cues such as location and pitch to un-mix the sources. In narrowly specified conditions all of these approaches have been shown to be useful; but in conditions closer to real application scenarios they individually fail. The PASCAL 'CHiME' challenge aims to encourage the development of more flexible approaches that combine the strengths of source separation techniques with those of speech and noise modelling. Compared to the demands of a genuine domestic speech recognition application, the PASCAL CHiME challenge has been somewhat simplified to make the competition more widely accessible, while still retaining the essential difficulty posed by additive noise. To this end, the ASR task is speaker dependent and employs a small but phonetically confusable vocabulary. Further, the microphone-speaker geometry remains fixed, focusing the task on the problems of additive noise rather than on the problem of channel variability that is also encountered in distant microphone speech processing. However, no compromise has been made with the noise background — the recordings come from a genuine living room (in a house with two small children!) measured over a period of several weeks. The SNRs employed in the challenge range between 9 dB down to -6 dB; a range resulting from the natural variation of the noise background rather than artificial scaling. In contrast to other noise robust speech recognition tasks, the utterances to be recognised, although supplied in a pre-segmented form, are locatable in a continuous audio stream that can also be downloaded, i.e., there are hours worth of acoustic context for each utterance. We hope participants will be able to exploit the continuous background data, for example, by learning spatial and spectral properties of the commonly occurring competing sound sources. Recordings have been made with binaural microphones. Although, larger microphone arrays would be more effective, the binaural configuration has particular interest: we hope by constraining the task to just two microphones, we will better enable engineers building solutions to robust ASR to trade insights with scientist trying to better understand human hearing. We hope you find this challenge both useful and fun. Details of how to take part are on the 'instructions' page. Good luck!
The figure to the right shows a time-frequency representation of a twenty second segment of domestic living room data that forms the background for the PASCAL 'CHiME' challenge. The figure illustrates some of the huge challenges presented by the target scenario: there is a noise floor that, although quasi-stationary, can change abruptly in response to unpredictable changes of state in the room (doors opening, appliances being turned on or off); on top of the background there are abrupt impact noises such as footsteps and doors banging that can mask even highly energetic portions of the speech signal; there may be multiple speakers in the room producing overlapping speech; the positions of the competing sound sources can change over time, etc, etc. There are many partial solutions to the problem of noise-robust ASR: systems either attempt to filter out the noise, directly model the combination of the noise and the speech or use signal-level cues such as location and pitch to un-mix the sources. In narrowly specified conditions all of these approaches have been shown to be useful; but in conditions closer to real application scenarios they individually fail. The PASCAL 'CHiME' challenge aims to encourage the development of more flexible approaches that combine the strengths of source separation techniques with those of speech and noise modelling. Compared to the demands of a genuine domestic speech recognition application, the PASCAL CHiME challenge has been somewhat simplified to make the competition more widely accessible, while still retaining the essential difficulty posed by additive noise. To this end, the ASR task is speaker dependent and employs a small but phonetically confusable vocabulary. Further, the microphone-speaker geometry remains fixed, focusing the task on the problems of additive noise rather than on the problem of channel variability that is also encountered in distant microphone speech processing. However, no compromise has been made with the noise background — the recordings come from a genuine living room (in a house with two small children!) measured over a period of several weeks. The SNRs employed in the challenge range between 9 dB down to -6 dB; a range resulting from the natural variation of the noise background rather than artificial scaling. In contrast to other noise robust speech recognition tasks, the utterances to be recognised, although supplied in a pre-segmented form, are locatable in a continuous audio stream that can also be downloaded, i.e., there are hours worth of acoustic context for each utterance. We hope participants will be able to exploit the continuous background data, for example, by learning spatial and spectral properties of the commonly occurring competing sound sources. Recordings have been made with binaural microphones. Although, larger microphone arrays would be more effective, the binaural configuration has particular interest: we hope by constraining the task to just two microphones, we will better enable engineers building solutions to robust ASR to trade insights with scientist trying to better understand human hearing. We hope you find this challenge both useful and fun. Details of how to take part are on the 'instructions' page. Good luck!