Baseline System
![]()
- This year CHiME-8 DASR baseline system is implemented using NeMo Conversational AI Toolkits [2].
- 🥇 The code for the best diarization system (NSD-MS2S) for last year’s CHiME-7 DASR has been made open-source !
- It was used in the USTC-NERCSLIP CHiME-7 DASR submission, have a look at previous year results.
Updated ESPNet CHiME-7 DASR Baseline
We updated last year CHiME-7 ESPNet baseline to be compatible with CHiME-8 DASR.
- The code is available as an ESPNet CHiME-8 recipe.
- It includes an end-to-end recipe for inference and new CHiME-8 DASR data generation and downloading.
The system here is effectively the same as used for the CHiME-7 DASR Challenge (except for some minor hyperparameter tuning of the clustering threshold).
Have a look at the README.md in the ESPNet CHiME-8 recipe for more details.
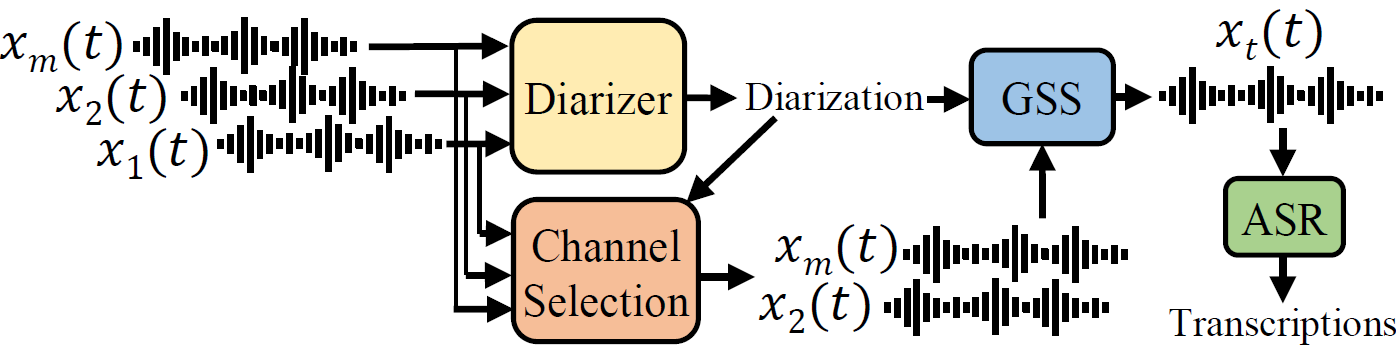
It is described in more detail in the CHiME-7 DASR paper and the page of the previous challenge.
The system consists of:
- a multi-channel diarization component based on Pyannote diarization pipeline 2.0.
- Envelope-variance selection [15] + Guided source separation [18] + WavLM+ transformer encoder/decoder ASR model.
Results are in results section here.
CHiME-8 DASR NeMo Baseline
It is built on top of the CHiME-7 DASR NeMo submission [30] which placed 5th last year.
It is available at chimechallenge.org/C8DASR-Baseline-NeMo.
- We included an end-to-end recipe for inference and new CHiME-8 DASR data generation and downloading.
- We also included hyperparameter optimization scripts for tuning diarization as well as the whole pipeline.
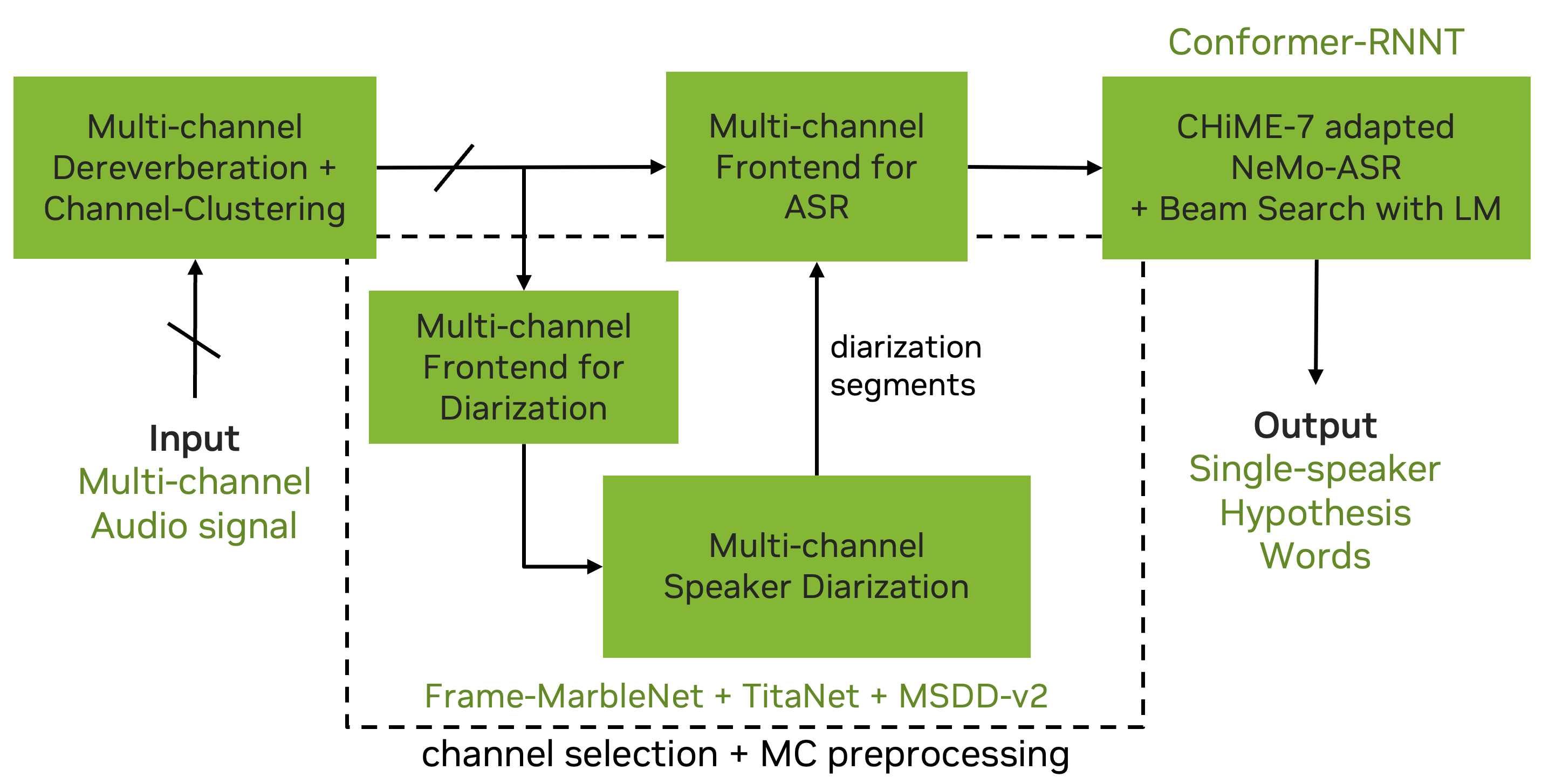
It consists of:
- Dereverberation + Channel Clustering + Speaker Diarization.
- Envelope Variance (EV) selection + GSS-based frontend.
- Monaural Conformer-Transducer ASR.
These are explained more in detail in the following and in NeMo CHiME-7 submission official paper [30].
Dereverberation + Channel Clustering + Speaker Diarization
Diarization Module Front-End
- MIMO-WPE Dereverberation
- dereverberation is applied over 40 s windows with a two-second overlap.
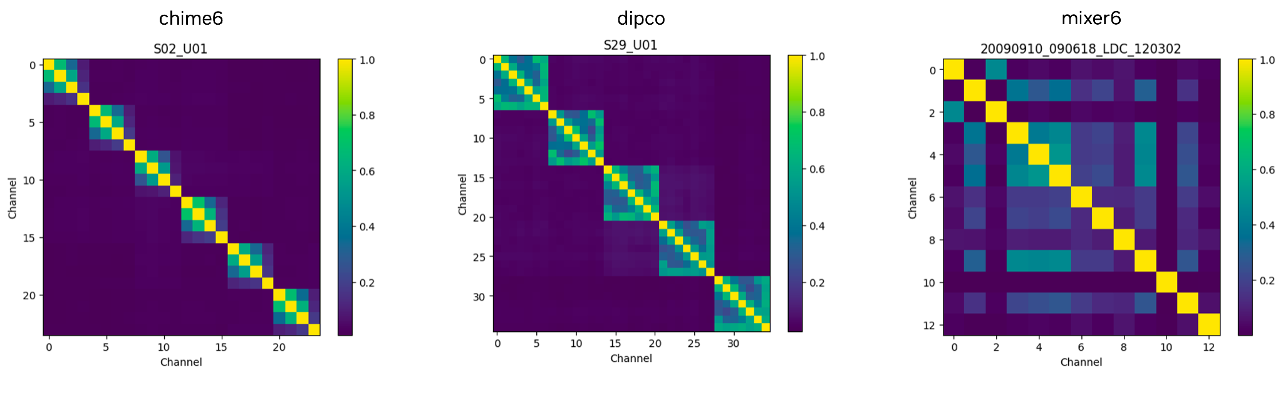
- Channel Clustering
- the dereverberated signal is used to calculate a spatial coherence matrix (see Figure 2), similarly as in [3], which is clustered using a normalized maximum eigengap spectral clustering [4].
- this allows to reduce the number of input channels for the downstream modules.
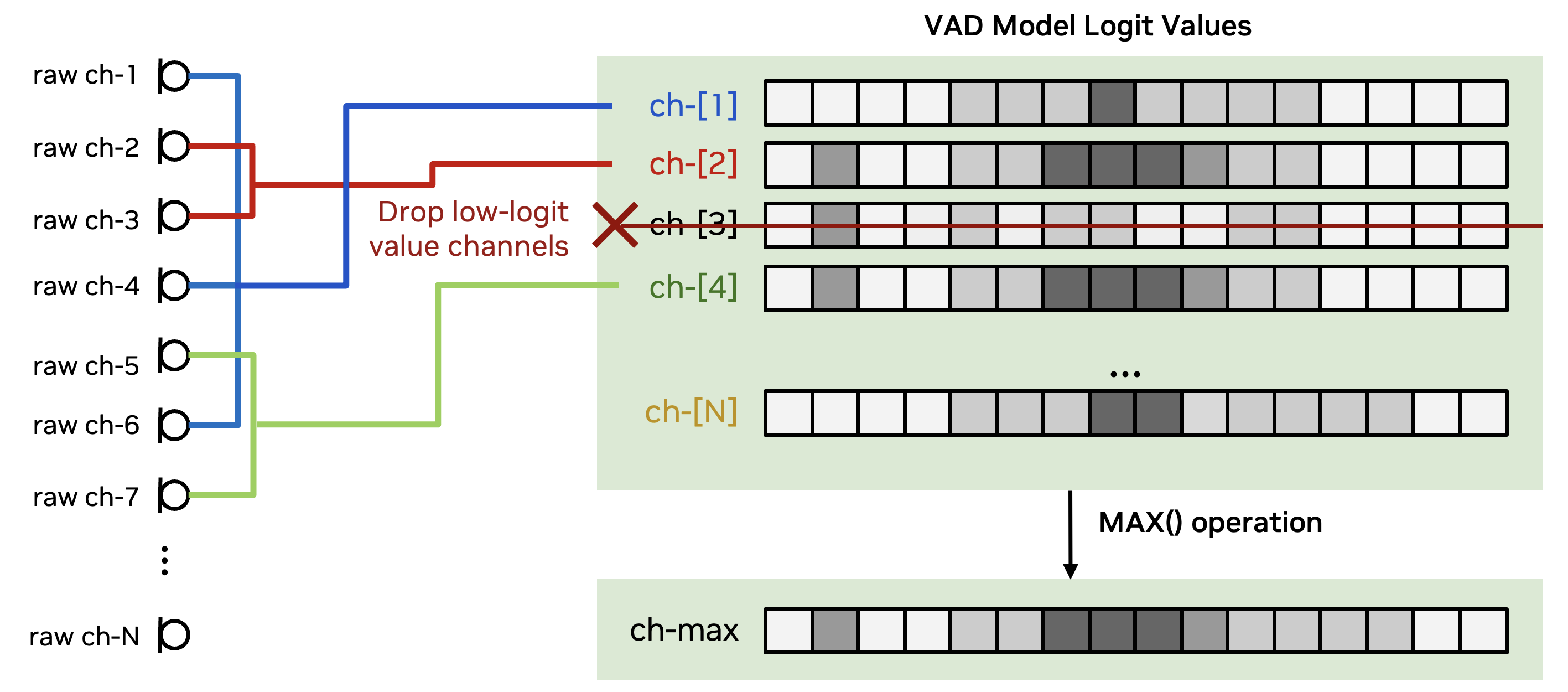
- Multi-channel VAD
- It is based on a MarbleNet which outputs a prediction each 20 ms [5].
- The model is trained on a combination of the CHiME-6 training subset and simulated data using NeMo multi-speaker data simulator [7] on Voxceleb1&2 datasets, resulting in a total of 2,000 hours.
- The VAD is monaural and is applied independently on all the clustered channels.
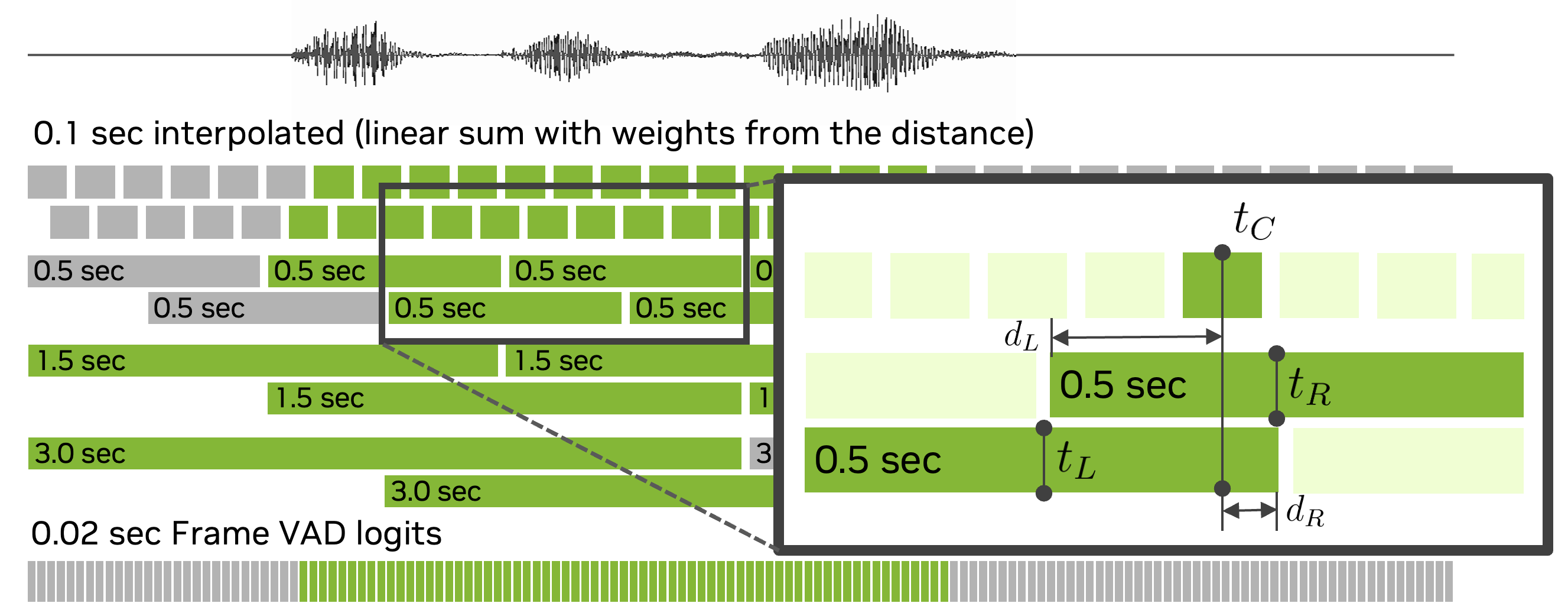
- Logits are fused by using a maximum operation channel-wise (see Figure 3).
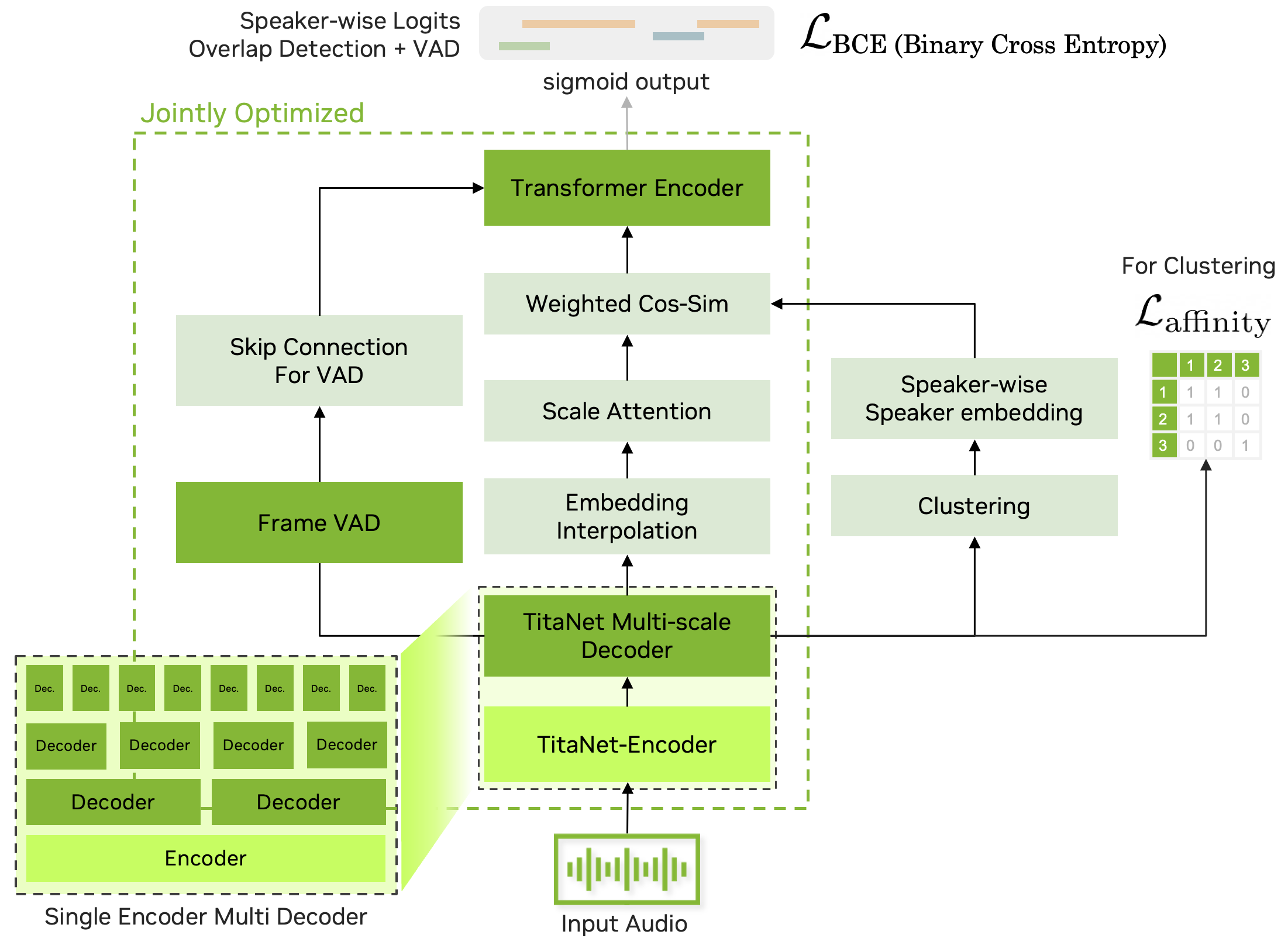
Multi-channel Diarization Module
The diarization component relies on the multiscale diarization decoder (MSDD) proposed in [12].
This system employs multi-scale embedding approach and utilizes TitaNet-large [13] speaker embedding extractor.
First, multi-scale Titanet embeddings are extracted with the procedure depicted in Figure 4. The VAD output is used to mask the portions of the input signals (after channel clustering) where there is no speech.
- Regarding multi-scale extraction we use scale lengths of 3 s, 1.5 s, and 0.5 s with a half-overlap.
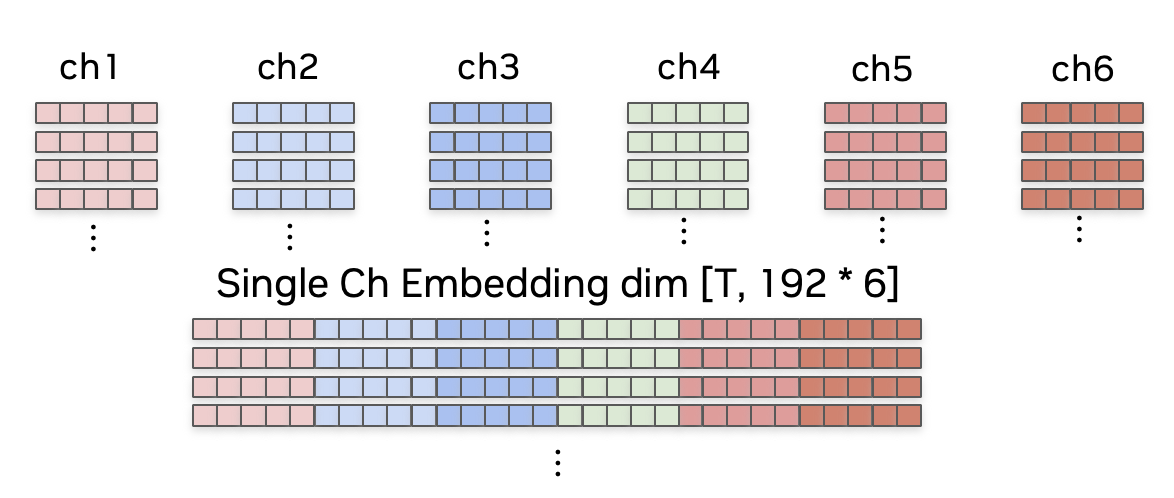
Such multi-scale speaker-id embeddings are then concatenated across all channels to obtain multi-channel multi-scale embeddings as depicted in Figure 5.
- In detail, for M clustered input channels, the channel that shows the lowest correlation of speaker embedding vector is excluded resulting in (M-1) concatenated embedding vectors.
Finally, these multi-channel multi-scale speaker embeddings are processed with a attention-based MSDD system (depicted in Figure 6).
- Unlike the system in [12], here we use four-layer Transformer architecture with a hidden size of 384.
- This MSDD model was trained on ~3,000 hours of audio mixture data generated from the same multi-speaker data simulator used for the VAD model.
- The MSDD inference window has 15s with 3s of hop length. The remainder of the training routine follows the system proposed in [12]. During inference, we use NME-SC clustering [4] for initialization clustering of the multi-channel multi-scale embeddings
- The global speaker clustering result is applied to each channel to produce separate channel-wise diarization outcomes which are then fused via majority voting.
EV-Selection + GSS-based frontend
The speech separation front-end is similar to one employed in last year CHiME-7 DASR ESPNet baseline [31].
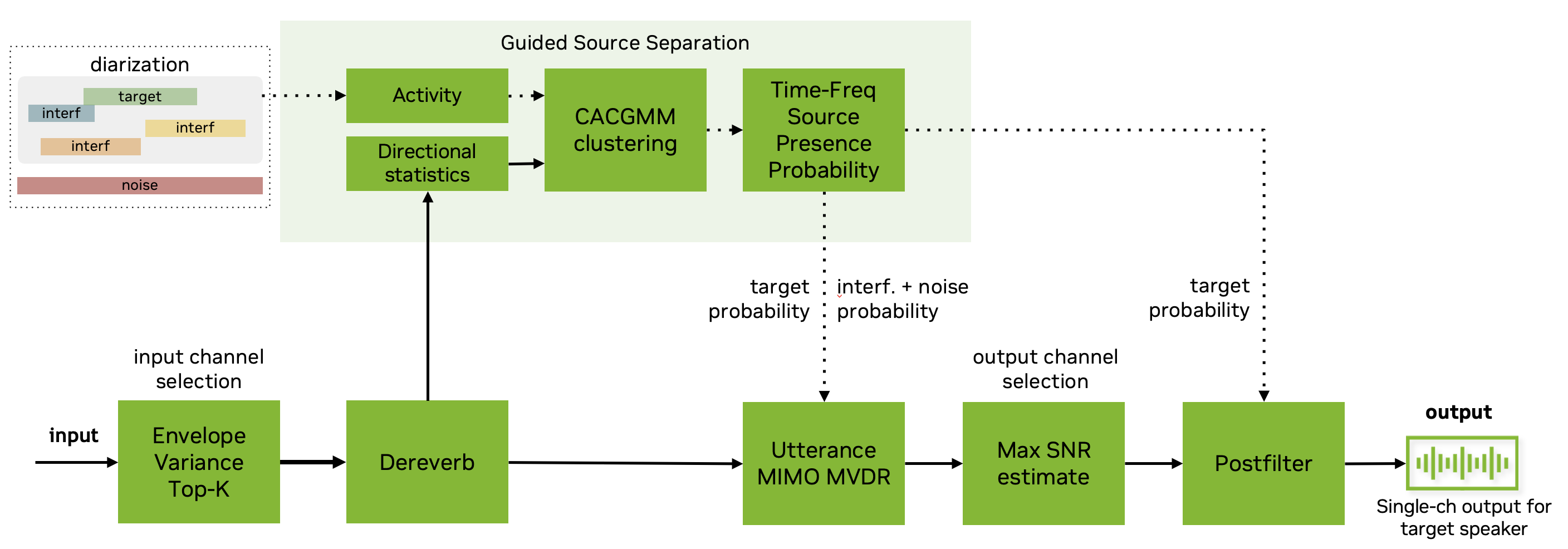
It consists of:
- Envelope variance (EV) based channel selection [15].
- MIMO dereverberation [1].
- Guided source separation (GSS) [18]
- employing a mask-based MIMO MVDR beamformer with a-posteriori maximum SNR channel selection.
Automatic Speech Recognition (ASR)
Each separated stream is transcribed using a Conformer-based transducer model [20].
The model was initialized using publicly available NeMo checkpoint [21] and fine-tuned using CHiME-7 train set (CHiME-6 and Mixer6 training subsets) after processing it through the GSS frontend using ground-truth diarization.
The model has 0.6B parameters and was fine-tuned for 35,000 updates with a batch size of 128.
Language Model (LM)
To improve ASR performance an N-gram language model is used.
We construct a word-piece level N-gram language model with byte-pair-encoding (BPE) tokens using SentencePiece [22,23] and KenLM [24,25] toolkits.
The language model is trained on the transcriptions of CHiME-7 train set.
Hyperparameter Optimization
For hyperparameter optimization we employ the Optuna framework [29].
We provide a diarization only tuning script and an end-to-end optimization script.
- diarization optimization
- The diarization only tuning script tunes the clustering parameters in order to minimize the macro DER. Speaker counting is particularly difficult with the highly diverse data in the 4 scenarios.
- end-to-end optimization
- tunes the hyperparameters of all modules at the same time, including LM rescoring and beam search decoding for ASR with respect to macro tcpWER.
Results
This year challenge significantly complicates speaker counting and tcpWER is severely impacted by the missed and false alarm speakers.
On one hand we have long meetings with 4 participants (CHiME-6) and on the other very short meetings of 2 (Mixer 6) or even 8 (NOTSOFAR1) speakers. This makes the choice of clustering hyperparameters extremely difficult.
CHiME-8 DASR NeMo Baseline
Scoring script output (see chime-utils).
###############################################################################
+-----+--------------+--------------+----------+----------+--------------+-------------+-----------------+------------------+------------------+------------------+
| | session_id | error_rate | errors | length | insertions | deletions | substitutions | missed_speaker | falarm_speaker | scored_speaker |
|-----+--------------+--------------+----------+----------+--------------+-------------+-----------------+------------------+------------------+------------------|
| dev | chime6 | 0.56532 | 34679 | 61344 | 5702 | 24502 | 4475 | 0 | 2 | 8 |
| dev | mixer6 | 0.248878 | 22404 | 90020 | 3591 | 9791 | 9022 | 0 | 0 | 70 |
| dev | dipco | 0.757875 | 12439 | 16413 | 3095 | 7605 | 1739 | 0 | 5 | 8 |
| dev | notsofar1 | 0.61031 | 92437 | 151459 | 11255 | 71229 | 9953 | 220 | 0 | 612 |
+-----+--------------+--------------+----------+----------+--------------+-------------+-----------------+------------------+------------------+------------------+
###############################################################################
### Macro-Averaged tcpWER for across all Scenario (Ranking Metric) ############
###############################################################################
+-----+--------------+
| | error_rate |
|-----+--------------|
| dev | 0.545596 |
+-----+--------------+
Updated ESPNet C7DASR Baseline
Scoring script output (see chime-utils).
###############################################################################
### tcpWER for all Scenario ###################################################
###############################################################################
+-----+--------------+--------------+----------+----------+--------------+-------------+-----------------+------------------+------------------+------------------+
| | session_id | error_rate | errors | length | insertions | deletions | substitutions | missed_speaker | falarm_speaker | scored_speaker |
|-----+--------------+--------------+----------+----------+--------------+-------------+-----------------+------------------+------------------+------------------|
| dev | chime6 | 0.887079 | 54417 | 61344 | 14542 | 29683 | 10192 | 0 | 4 | 8 |
| dev | mixer6 | 0.292346 | 26317 | 90020 | 4656 | 9079 | 12582 | 0 | 23 | 70 |
| dev | dipco | 0.984403 | 16157 | 16413 | 5008 | 8507 | 2642 | 3 | 0 | 8 |
| dev | notsofar1 | 0.462402 | 70035 | 151459 | 13116 | 37324 | 19595 | 120 | 5 | 612 |
+-----+--------------+--------------+----------+----------+--------------+-------------+-----------------+------------------+------------------+------------------+
###############################################################################
### Macro-Averaged tcpWER for across all Scenario (Ranking Metric) ############
###############################################################################
+-----+--------------+
| | error_rate |
|-----+--------------|
| dev | 0.656558 |
+-----+--------------+
📩 Contact
For questions or help, you can reach the organizers via CHiME Google Group or via CHiME Slack Workspace.
References
[1] T. Yoshioka and T. Nakatani, “Generalization of multichannel linear prediction methods for blind MIMO impulse response shortening,” IEEE Trans. Audio, Speech, and Lang. Process., vol. 20, no. 10, pp. 2707–2720, 2012.
[2] O. Kuchaiev et al., “NeMo: a toolkit for building AI applications using neural modules,” in Proc. Systems for ML Worshop, NeurIPS, 2019.
[3] A. J. Mu ̃noz-Montoro, P. Vera-Candeas, and M. G. Christensen, “A coherence-based clustering method for multichannel speech enhancement in wireless acoustic sensor networks,” in Proc. EU-SIPCO, 2021, pp. 1130–1134.
[4] T. J. Park et al., “Auto-tuning spectral clustering for speaker diarization using normalized maximum eigengap,” IEEE Signal Processing Letters, vol. 27, pp. 381–385, 2020.
[5] NVIDIA, “Speech to frame label,” https://github.com/NVIDIA/NeMo/blob/main/examples/asr/speech classification/speech to frame label.py, [Online; accessed July 17, 2023].
[6] S. Watanabe et al., “CHiME-6 Challenge: Tackling Multispeaker Speech Recognition for Unsegmented Recordings,” in Proc. CHiME-6 Workshop, 2020, pp. 1–7.
[7] NVIDIA, “Speech data simulator,” https://github.com/NVIDIA/NeMo/tree/main/tools/speech data simulator, [Online; accessed July 17, 2023].
[8] A. Nagrani et al., “Voxceleb: a large-scale speaker identification dataset,” arXiv preprint arXiv:1706.08612, 2017.
[9] J. S. Chung, A. Nagrani, and A. Zisserman, “Voxceleb2: Deep speaker recognition,” arXiv preprint arXiv:1806.05622, 2018.
[10] D. S. Park et al., “Specaugment: A simple data augmentation method for automatic speech recognition,” arXiv preprint arXiv:1904.08779, 2019.
[11] D. Snyder, G. Chen, and D. Povey, “Musan: A music, speech, and noise corpus,” arXiv preprint arXiv:1510.08484, 2015.
[12] T. J. Park et al., “Multi-scale speaker diarization with dynamic scale weighting,” arXiv preprint arXiv:2203.15974, 2022.
[13] N. R. Koluguri, T. Park, and B. Ginsburg, “TitaNet: Neural model for speaker representation with 1d depth-wise separable convolutions and global context,” in Proc. ICASSP, 2022, pp. 8102–8106.
[14] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an asr corpus based on public domain audiobooks,” in Proc. ICASSP, 2015, pp. 5206–5210.
[15] M. Wolf and C. Nadeu, “Channel selection measures for multimi- crophone speech recognition,” Speech Comm., vol. 57, pp. 170– 180, 2014.
[16] I. Medennikov et al., “The STC system for the CHiME-6 challenge,” in Proc. CHiME Workshop, 2020.
[17] M. Souden, J. Benesty, and S. Affes, “On optimal frequency domain multichannel linear filtering for noise reduction,” IEEE Trans. on Audio, Speech, and Lang. Process., vol. 18, no. 2, pp. 260–276, 2009.
[18] C. Boeddeker et al., “Front-end processing for the CHiME-5 dinner party scenario,” in Proc. CHiME-5 Workshop, 2018.
[19] A. Laptev and B. Ginsburg, “Fast entropy-based methods of word-level confidence estimation for end-to-end automatic speech recognition,” in Proc. IEEE Spoken Language Technology Work- shop (SLT), 2023, pp. 152–159.
[20] A. Gulati et al., “Conformer: Convolution-augmented transformer for speech recognition,” in Proc. Interspeech, 2020.
[21] NVIDIA, “Conformer Transducer XL,” https://catalog.ngc. nvidia.com/orgs/nvidia/teams/nemo/models/stt en conformer transducer xlarge, [Online; accessed July 17, 2023].
[22] T. Kudo and J. Richardson, “SentencePiece: A simple and lan- guage independent subword tokenizer and detokenizer for neural text processing,” in Proc. EMNLP: System Demonstrations, Nov. 2018, pp. 66–71.
[23] Google, “SentencePiece,” https://github.com/google/ sentencepiece, [Online; accessed July 17, 2023].
[24] K. Heafield, “KenLM: Faster and smaller language model queries,” in Proc. Workshop on Statistical Machine Translation, Jul. 2011, pp. 187–197.
[25] ——, “kenlm,” https://github.com/kpu/kenlm, [Online; accessed July 17, 2023].
[26] B. Roark et al., “The OpenGrm open-source finite-state grammar software libraries,” in Proc. ACL 2012 System Demonstrations, Jul. 2012, pp. 61–66.
[27] ——, “OpenGrm NGram Library,” https://www.opengrm.org/ twiki/bin/view/GRM/NGramLibrary, [Online; accessed July 17, 2023].
[28] J. Kim, Y. Lee, and E. Kim, “Accelerating RNN transducer inference via adaptive expansion search,” IEEE Signal Process. Let- ters, vol. 27, pp. 2019–2023, 2020.
[29] T. Akiba et al., “Optuna: A next-generation hyperparameter optimization framework,” in Proc. ACM SIGKDD Intl. Conf. on Knowledge Discovery and Data Mining [30] Park, Tae Jin, et al. The CHiME-7 Challenge: System Description and Performance of NeMo Team’s DASR System. arXiv preprint arXiv:2310.12378, 2023. [31] Cornell, S., Wiesner, M., Watanabe, S., Raj, D., Chang, X., Garcia, P., … & Khudanpur, S. (2023). The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios. arXiv preprint arXiv:2306.13734.