Task 1 - DASR
Distant Automatic Speech Recognition (DASR) with Multiple Devices in Diverse Scenarios.

![]()
![]()
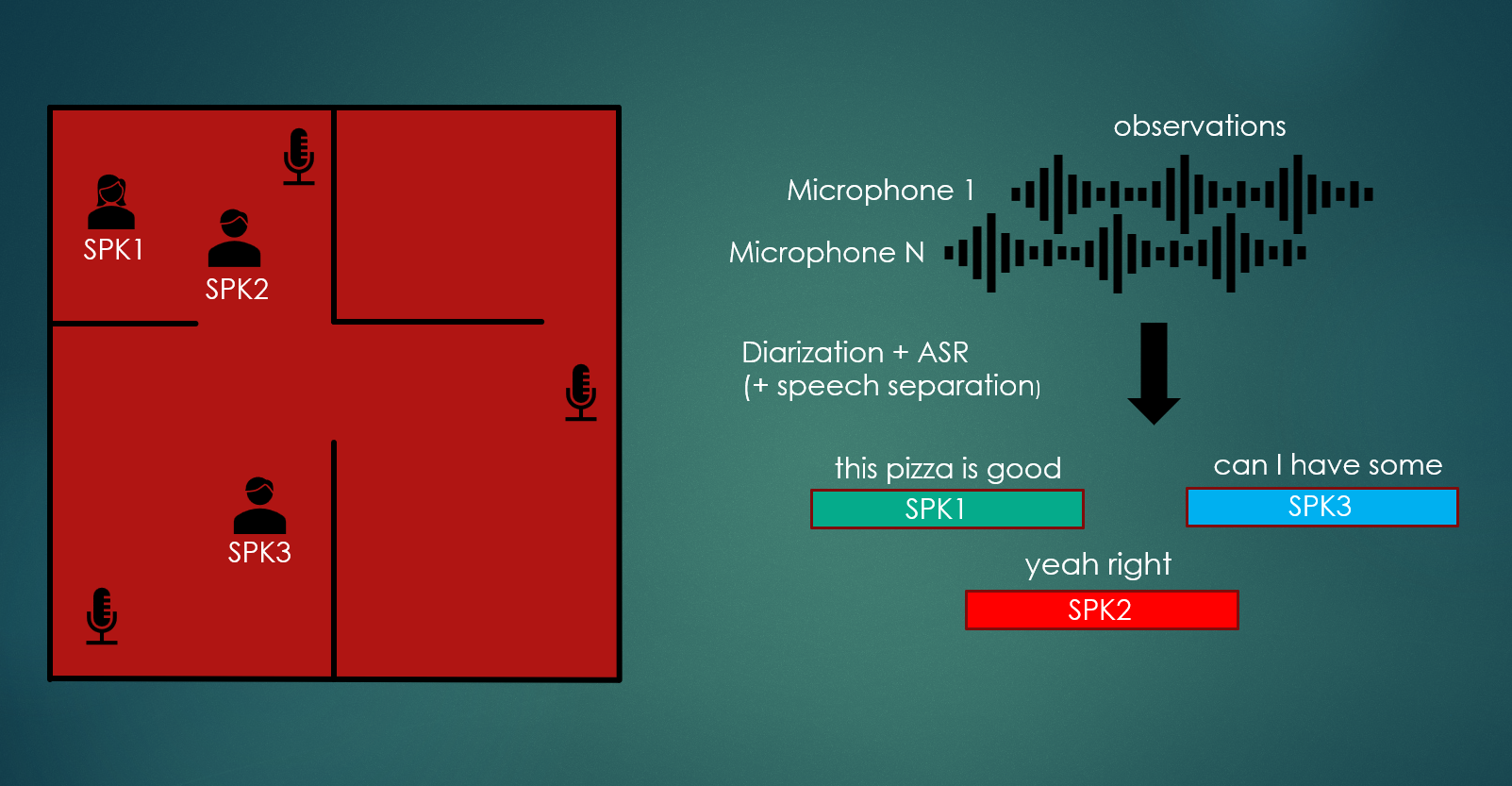
This Task focuses on distant automatic speech transcription and segmentation with multiple recording devices.
The goal of each participant is to devise an automated system that can tackle this problem, and is able to generalize across different array topologies and different application scenarios: meetings, dinner parties and interviews.
Participants can possibly exploit commonly used open-source datasets (e.g. Librispeech) and pre-trained models. In detail, this includes popular self-supervised representation (SSLR) models (see Rules Section for a complete list).
A pre-print of the Task and Baseline description is now available on arXiv).
Important Dates
Have a look at Important Dates page.
CHiME-2023 Workshop
All participants are expected to present their work at the CHiME-2023 workshop.
See workshop page for more details.
They also are encouraged to extend their system description paper and submit a full-paper (3 to 6 pages, references included) after the workshop (see Important Dates )] which will be in the ISCA archive and appear in the workshop proceedings. The proceedings will be registered (ISBN) and indexed (by Thomson-Reuters and Elsevier).
Registration
If you want to participate, please register by filling this Google Form. Please submit only one form per team.
Contact Us/Stay Tuned
If you are considering participating or just want to learn more then please join the CHiME Google Group.
We have also a CHiME Slack Workspace.
Follow us on Twitter, we will also use that to make announcements.
Short Description
Task training, development, and evaluation data comes from three different datasets: CHiME-6 [1], DipCO [2] and Mixer 6 Speech [3].
These datasets have different characteristics and, as mentioned earlier, we are interested in pushing research towards multi-talker transcription systems that can handle a wide variety of scenarios, including, but not limited to, the following:
- Generalize across different recording setups, such as linear arrays (e.g. CHiME-6), circular arrays (DiPCo), or ad-hoc microphones (Mixer 6 Speech)
- Handle different number of participant in each dataset
- Handle inherent diversity in lexicon due to possibly different settings (e.g more formal or informal)
- Wide variation in acoustic quality (e.g. signal-to-noise ratio, reverberation)
Crucially, participants are forbidden to use automatic domain identification (or manual identification, e.g., based on number of channels) to switch between different systems/hyper-parameters/configurations.
A single common system able to adapt to the different scenarios and microphone configurations has to be devised.
The final ranking will be obtained via speaker-attributed word error rate (SA-WER) macro-averaged across the three datasets, as we are interested in generalization across the different scenarios. The speaker-transcript attribution is performed here via diarization, so we can also call this diarization-attributed WER (DA-WER) to distinguish it from other definitions of SA-WER. It will be explained in detail thereafter.
Participants will be required to submit JSON based annotation with this format (similar to CHiME-6 one here, one JSON item for each utterance), containing both diarization information and transcriptions for each utterance:
{
"end_time": "43.82",
"start_time": "40.60",
"words": "it's the blue",
"speaker": "P05",
"session_id": "S02"
},
Diarization error rate (DER) is used to find the best speaker-id permutation between oracle annotation and submitted annotation, then WER statistics (deletions, substitutions etc.) are accumulated for each dataset and finally macro WER is computed across the three evaluation datasets.
The process is depicted in the figure below:

We can call this metric also DA-WER as it is diarization assigned, to distinguish it from other SA-WER “flavors” e.g. NIST 2009 Rich Transcription Meeting Recognition Evaluation Plan. One advantage over asclite is the fact that it does not require per-word boundaries, for which is hard to define a ground truth in many instances. A possible disadvantage is that some errors are counted twice: e.g. a wrongly assigned word will count as an insertion for one speaker and a deletion for the other. This is because we consider each speaker transcript independently and not jointly.
For this reason participants are required to obtain reasonable segmentation (i.e. time marks) plus transcripts for each speaker. In fact, in many applications, it is desiderable to have reasonably audio-aligned transcriptions, e.g. in order to double check them easily.
While participants submissions will be ranked according this macro-averaged DA-WER, we will also report diarization error rate (DER) and jaccard error rate (JER) for each submissions (also macro-averaged.
See Submission page for more information about systems evaluation and ranking.
See Rules page for more information on what information participants system can use in training and inference.
Main Track and Sub-Tracks
The proposed Task has one main track and one sub-track, both inherited directly from the previous CHiME-6 Challenge.
Important
Participants must always submit to the main track while submission to the sub-track is optional.
Main Track
This is the main focus of this Task and is the one explained above: participants need to design an automatic system for segmentation and trascription of conversations between multiple participants, using possibly heterogeneous far-field devices.
No prior or oracle information is available in evaluation (e.g. reference device for each utterance, number of total speakers in each session etc). See the Rules page for additional information.
Performance is measured as described above, using macro-averaged SA-WER.
Far-Field Acoustic Robustness Sub-Track
In this sub-track participants can use oracle segmentation. It is similar to CHiME-6 Challenge Track 1. The only exception here is that we do not provide a reference device, so participants have to devise an automatic method on how to select the best device or fuse information across devices. Again, performance and ranking will be determined using macro-averaged SA-WER described above.
What about Diarization ?
If you are only interested in diarization performance you can use our baseline system (ASR plus guided source separation) for the far-field robustness sub-track to participate in the main track and get diarization results plus ASR results.
As said, we will report both SA-WER, DER and JER so even if your system will not rank first according to SA-WER state-of-the-art results according to diarization performance will also be highly regarded.
In a previous draft we planned to make an additional diarization track but we removed it for simplicity, as participation to the main track is mandatory anyway. The fact that participants can submit up to 3 systems could encourage participants to explore different trade-offs between diarization and ASR performance.
For More Details:
Motivation
This Task builds upon the previous CHiME-6 Challenge and adds the following novelties:
- Motivated by recent achievements in SSLR, we allow participants to exploit open-source SSLR models e.g. Wav2Vec 2.0 and WavLM (complete list in Rules page).
- Evaluation and training material is expanded by including Dinner Party Corpus (DipCO) and Mixer 6 Speech datasets.
As such, participants systems are required to generalize to different array topologies possibly consisting of heterogeneous recording devices, and to handle a variable number of speakers in the whole meeting. - One limitation in the CHiME-6 Challenge was the fact that using external data was forbidden. This prevented the possibility of using, for example, supervised DNN-based speech separation and enhancement techniques, which require oracle clean speech/sources for training. Here we allow participants to use some of the most common datasets used for creating synthetic datasets: e.g. FSD50k, Librispeech et cetera. Participants are free to propose additional open-source materials till the second week from the start of the Challenge (see Rules).
- Submissions will be ranked according to macro averaged DA-WER (SA-WER with diarization assigned speaker mapping).
The macro-average is taken across the three evaluation scenarios: CHiME-6, DipCO and Mixer 6.
This because in this task we are fundamentally interested in how a system can generalize to different meeting scenarios with different devices, number of participants and acoustic conditions.
The scientific questions this Task aims to investigate include:
- Can we significantly improve the performance by leveraging SSLR on such a challenging task? Since most SSLR models are trained on monaural signals, how to integrate and leverage them in multi-channel distant speech scenarios?
- Can synthetic datasets be effectively leveraged to improve acoustic robustness in real-world multi-party spontaneous conversations? One popular way is training a suitable front-end to perform enhancement and/or separation and fine-tuning it with the ASR back-end.
- Can we devise a single system that generalizes and is effective across different microphone networks (including ad-hoc, unseen ones) and acoustic environments ?
- How much does each component in a complex multi-channel diarization + ASR pipeline contributes to the final segmentation and recognition score ?
[1] Watanabe, S., Mandel, M., Barker, J., Vincent, E., Arora, A., Chang, X., et al. CHiME-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings. https://arxiv.org/abs/2004.09249
[2] Van Segbroeck, M., Zaid, A., Kutsenko, K., Huerta, C., Nguyen, T., Luo, X., et al. (2019). DiPCo–Dinner Party Corpus. https://arxiv.org/abs/1909.13447
[3] Brandschain, L., Graff, D., Cieri, C., Walker, K., Caruso, C., & Neely, A. (2010, May). Mixer 6. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10).