Rules
Summary of the rules for systems participating in the challenge:
- For building the system, it is allowed to use the training subset of MMCSG dataset and external data listed in the subsection Data and pre-trained models. If you believe there is some public dataset missing, you can propose it to be added until the deadline as specified in the schedule.
- The development subset of MMCSG can be used for evaluating the system throughout the challenge period, but not for training or automatic tuning of the systems.
- Pre-trained models are listed in the “Data and pre-trained models” subsection. Only those pre-trained models are allowed to be used. If you believe there is some model missing, you can propose it to be added until the deadline as specified in the schedule.
- We are interested in streaming systems, i.e. systems that process their inputs sequentially in time and specify latency for each emitted word, as described in detail in the subsection Evaluation. They must not use any global information from a recording before processing it in temporal order. Such global information could include global normalizations, non-streaming speaker identification or diarization, etc. This requirement on streaming processing applies to all modalities (audio, visual, accelerometer, gyroscope, etc). Non-streaming systems can still be submitted and will be ranked in a category for systems with latency >1000ms. For these systems, please provide the word-timestamps as the length of the entire recording, to indicate that the system uses global information.
- The details of the streaming nature of the system, including any lookahead, chunk-based processing, other details that would impact latency, and an explicit estimate of the average algorithmic and emission latency itself should be clearly described in a section of the submitted system description with the heading “Latency”.
- For evaluation, each recording must be considered separately. The system should not be in any way fine-tuned on the entire evaluation set (e.g. by computing global statistics, gathering speaker information across multiple recordings). If your system does not comply with these rules (e.g. by using a private dataset), you may still submit your system, but we will not include it in the final rankings.
Evaluation
The submitted systems will be evaluated on speech recognition performance using multitalker word error rate for the latency thresholds: 1000ms, 350ms, 150ms. The average latency of correctly recognized words is computed for each system and then the system is classified into one of four categories based on these thresholds. Systems within the same category will be compared to one another using multitalker word error rate.
To do this, there are two main pieces of additional information that the systems need to provide in the hypotheses:
- speaker attribution: each word in the hypothesis must be attributed to SELF or OTHER speaker
- word time-stamps: each word must has a time-stamp corresponding to when the word was decoded (more details below)
Multitalker word error rate evaluates the transcription of SELF and OTHER speakers jointly and it expects the words to be correctly attributed to these two speakers. It breaks down the error into substitutions, insertions, deletions and speaker-attribution errors.
As an example, for the following conversation:

with the hypothesis provided by the system including speaker attributions as:

The alignment computed by the multitalker WER is as follows:

Note that some words (‘yes’) are both substituted and mis-attributed. For these types of errors, we choose to include them into speaker-attribution errors. The final multitalker WER is then computed for SELF and OTHER as:
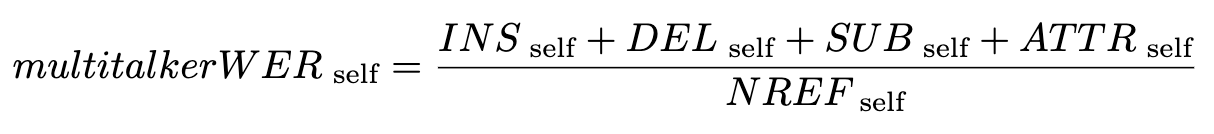
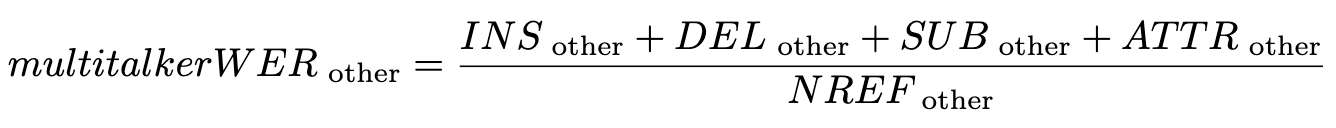
where NREF is the number of reference words. ATTR_self denotes words of SELF that are attributed to OTHER, and vice versa. In the example above:
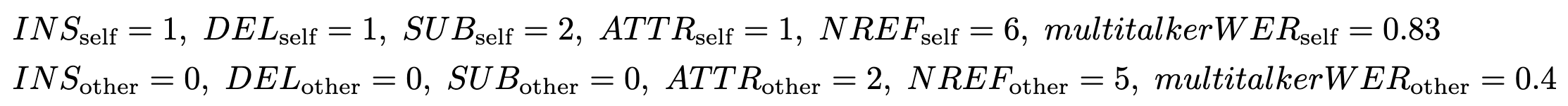
Before computing multitalker WER, both reference and transcription are normalized, by removing punctuation, normalizing capitalization and performing permitted substitutions defined in this file. For evaluation of latency, we consider algorithmic and emission latency of the system, not computational latency. That is, we assume that the computation of the forward pass through the system is instant and we are not asking for actual measurements of the wall-clock time necessary to run the system (even though we encourage reporting that). Instead, we require the systems to provide the information of how much of the input signal the system used to emit each of the words. For example, in the hypothesis above, the word-timestamps (in seconds) could look as follows:

Here, timestamp 1.62 for word “ehm” means that the system had processed 1.62 seconds of the input recording when finished emitting the entire word “ehm”. The measurement of the word-timestamps needs to take into account the look-ahead of the model, as well as any emission latency that the model learned to have. The most simple way to obtain the timestamps reliably (which is also used in the baseline system) is to implement the inference chunk-by-chunk and use the end of the chunk as the timestamp for any words emitted during the processing of this chunk. Two examples of how the timestamps would be defined for different types of systems are here and here. Please contact us, if you are unsure how to derive the timestamps for your type of system.
To test whether the word-timestamps, which you provide with the hypothesis, are correctly reflecting the functioning of your system, you might try to pass a signal perturbed from certain time t onward. All words that originally had timestamps < t should remain the same as with the original signal.
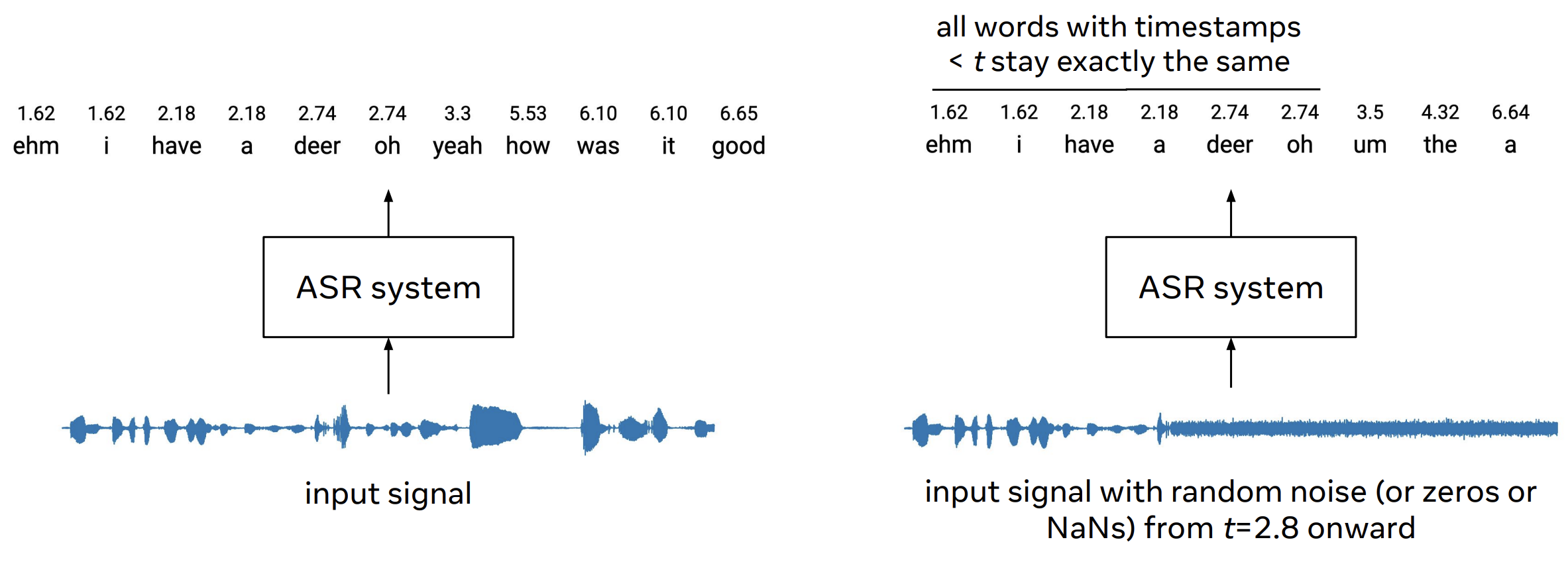
We provide scripts to perform this test on a subset of recordings at our Github repo. As part of the submission, we will ask for the outputs of this test. We encourage the participants to perform this test during the development of their systems as it is easy to overlook some aspects that could make the system non-streaming (such as global normalizations, beam search leading to corrections in the past decoded words, etc).
The evaluation script accepts the hypothesis in the same format as the provided references, that is one TSV file per recording. More information on the format and on how to run the evaluation is provided in the Github README. During submission, the participants will provide the transcription files and the evaluated scores using the provided evaluation script. Furthermore, the participants are required to submit a system description. Publishing of scripts to reproduce the submitted systems is encouraged, but not required.
External data and pre-trained models
Besides the MMCSG dataset published with this challenge, the participants are allowed to use public datasets and pre-trained models listed below. In case you want to propose additional dataset or pre-trained model to be added to these lists, do so by contacting us at Slack until March 20th ‘24. If you want to use a private dataset or model, you may still submit your system to the challenge, but we will not include it in the final rankings.
Participants may use these publicly available datasets for building the systems:
- AMI
- LibriSpeech
- TEDLIUM
- MUSAN
- RWCP Sound Scene Database
- REVERB Challenge RIRs.
- Aachen AIR dataset.
- BUT Reverb database.
- SLR28 RIR and Noise Database (contains Aachen AIR, MUSAN noise, RWCP sound scene database and REVERB challenge RIRs, plus simulated ones).
- VoxCeleb 1&2
- FSD50k
- WSJ0-2mix, WHAM, WHAMR, WSJ
- SINS
- LibriCSS acoustic transfer functions (ATF)
- NOTSOFAR1 simulated CSS dataset
- Ego4D
- Project Aria Datasets
- DNS challenge noises
In addition, following pre-trained models may be used:
- Wav2vec:
- Wav2vec 2.0:
- Fairseq:
- All models including Wav2Vec 2.0 Large (LV-60 + CV + SWBD + FSH) and the multi-lingual XLSR-53 56k
- Torchaudio:
- Huggingface:
- facebook/wav2vec2-base-960h
- facebook/wav2vec2-large-960h
- facebook/wav2vec2-large-960h-lv60-self
- facebook/wav2vec2-base
- facebook/wav2vec2-large-lv60
- facebook/wav2vec2-large-xlsr-53
- wav2vec2-large lv60 + speaker verification
- Other models on Huggingface using the same weights as the Fairseq ones.
- S3PRL
- Fairseq:
- HuBERT
- WavLM
- Tacotron2
- ECAPA-TDNN
- X-vector extractor
- Pyannote Segmentation
- Pyannote Diarization (Pyannote Segmentation+ECAPA-TDNN from SpeechBrain)
- NeMo toolkit ASR pre-trained models:
- NeMo toolkit speaker ID embeddings models:
- NeMo toolkit VAD models:
- NeMo toolkit diarization models:
- Whisper
- OWSM: Open Whisper-style Speech Model
- Icefall Zipformer
- RWKV Transducer