Baseline System
The baseline system is provided at Github. Please refer to the README therein for information about how to install and run the system.
We provide two different baseline systems:
- Baseline starting from public pre-trained model, which is fine-tuned on the in-domain MMCSG dataset. This baseline provides the most competitive results.
- Baseline starting from scratch, trained on simulated data and fine-tuned on the in-domain MMCSG dataset. This baseline showcases the tools to simulate multi-channel multi-talker recordings and can be a good starting point for participants who do not wish to use a pre-trained model.
Both baseline systems roughly follow the scheme in (Lin et al, 2023). It comprises of:
- Fixed NLCMV beamformer (Feng et al, 2023), which uses 13 beams into 12 directions uniformly spaced around the wearer + 1 direction for the mouth of the wearer. The beamformer channels go clock-wise from channel-0 being 12-o’clock to channel-11 being 11-o’clock. The last channel, channel-12 is the mouth. The beamformer coefficients are derived from acoustic transfer functions (ATF) recorded in anechoic rooms with the Aria glasses. We release both the beamforming coefficients and the original ATFs.
- Extraction of log-mel features from each of the 13 beams
- ASR model processing the multi-channel features and estimating serialized-output-training (SOT) (Kanda et al, 2022) transcriptions

The first baseline system uses an ASR model based on a publicly available pre-trained streaming model - FastConformer Hybrid Transducer-CTC model. By default, this model is a single-speaker, single-channel model. We modify this model by prepending the beamformer, extending its input to multiple channels, extending the tokenizer with speaker tokens »0, »1 (for SELF and OTHER, respectively), and fine-tuning it to provide the SOT transcriptions. The fine-tuning is done on the training subset of the MMCSG dataset.
The second baseline system (trained from scratch) uses the same ASR model architecture, but is trained from scratch on data simulated from Librispeech, TEDLIUM speech datasets, DNS challenge noise recordings and room impulse responses recorded with Aria glasses.
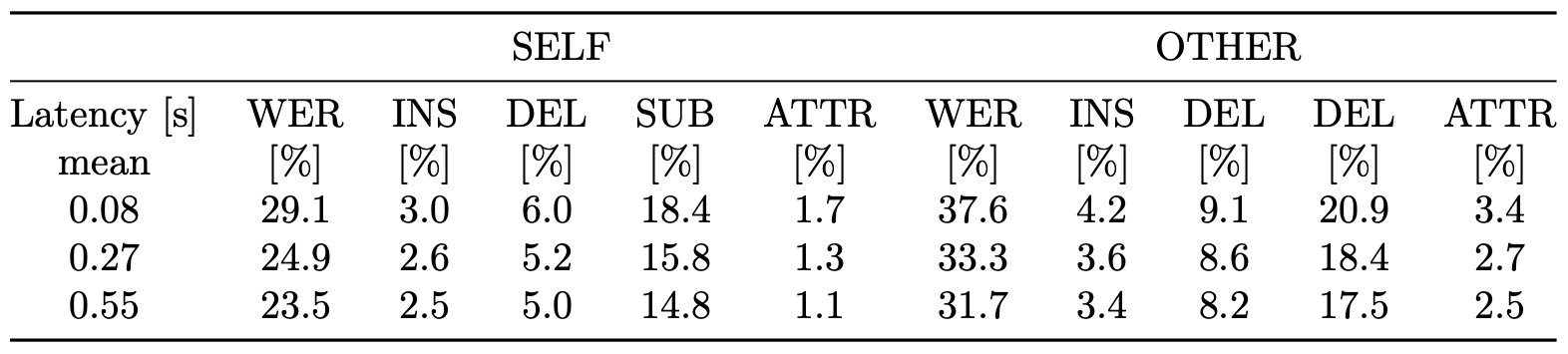
The results achieved by the baseline systems on the dev subset of MMCSG with several different latency settings are summarized in the following tables:
For the first baseline system using a pre-trained model:
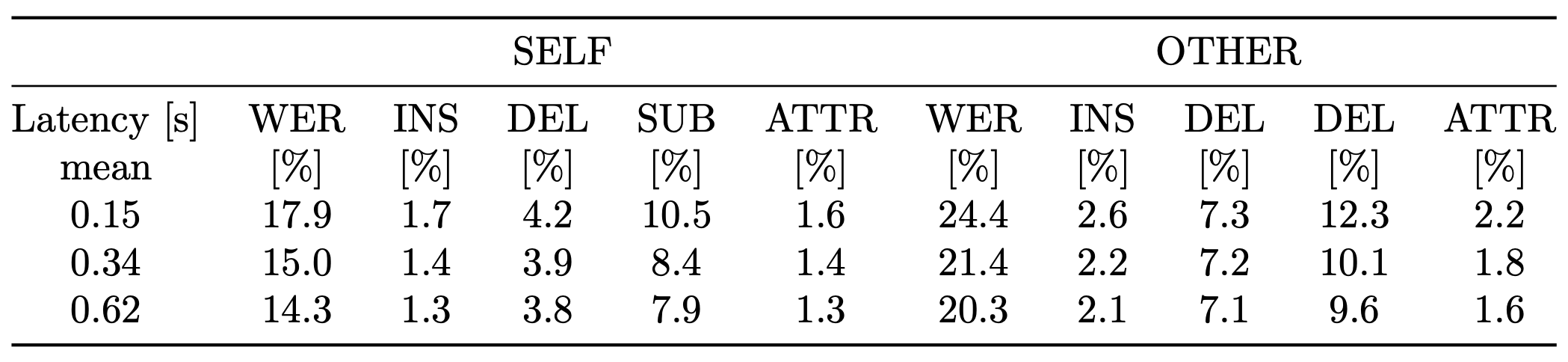
For the baseline system trained from scratch: