Data
The main MMCSG dataset for this task consists of recordings between two conversation partners using Aria glasses (Project Aria). The collected data is split into training, development, and evaluation subsets. The evaluation subset will remain hidden until shortly before the final submission of the systems. In the baseline system, a training subset is used to build the system, while the results are reported on the development subset. The participants can use the training subsets to build their systems and the development set to evaluate and compare to the baseline. No training or automatic tuning is allowed on the development set.
| number of recordings | duration | avg duration per recording | number of speakers | |
|---|---|---|---|---|
| train | 172 | 8.5 h | 3 min | 49 |
| dev | 169 | 8.4 h | 3 min | 45 |
| eval | 189 | 9.4 h | 3 min | 44 |
Besides the MMCSG dataset, public datasets as listed in the Rules page can be used.
In addition to the MMCSG dataset, we also publish MCAS dataset, which can help the participants to build their systems. The MCAS dataset contains the following:
- Real room impulse responses recorded with the Aria glasses
- Simulated room impulse responses using the co-ordinates of the microphones of Aria glasses
- Acoustic transfer function recorded with the Aria glasses in an anechoic room
Description of the MMCSG data
The MMCSG dataset consists of 172 recordings for training (released on February 15th 2024), 169 recordings for development (released on February 15th 2024) and 189 recordings for evaluation (will be released on June 15th ‘24). Each recording features a conversation of two conversation participants with optional background noise. Both conversation participants are wearing Aria glasses to record the conversation. For system development and evaluation only the recordings of one of the devices are allowed to be used at the same time. The wearer of the glasses will be referred to as SELF, while the conversational partner as OTHER. Note that there is a third person in the room, the moderator, who is present in some of the video recordings, but does not speak.
Each recording consists of the following modalities:
- audio (7 channels), recorded at 48kHz
- RGB video (with blurred faces to maintain privacy), recorded with 15fps, a resolution of 720x720, and 8bpp
- Inertial measurement unit (model BMI085), accelerometer and gyroscope each recorded at a sampling rate 1kHz
For details about the recording device, please refer to the section “Aria glasses”. The data were labeled by human annotators who marked the segments where each of the two speakers is active, transcribed the speech of these segments and labeled which of the speakers is wearing the glasses (i.e. which speaker is SELF and OTHER).
Detailed desciption of data structure and formats
The directory structure is as follows (note that the evaluation subdirectories for transcriptions, rttm and metadata will be distributed only after the end of the challenge):
├── audio
│ ├── train
│ ├── dev
│ └── eval
├── video
│ ├── train
│ ├── dev
│ └── eval
├── accelerometer
│ ├── train
│ ├── dev
│ └── eval
├── gyroscope
│ ├── train
│ ├── dev
│ └── eval
├── transcriptions
│ ├── train
│ ├── dev
│ └── eval
├── rttm
│ ├── train
│ ├── dev
│ └── eval
└── metadata
├── train
├── dev
└── eval
Formats of the data in the subdirectories are as follows:
audiocontains WAV files with 7-channel recordings, with 48 kHz sampling rate. The stem of the audio file name will be used as ID of the recording in all the subsequent filenames and lists (<recording-id>.wav).videocontains mp4 files (<recording-id>.mp4) with the recordings obtained from the RGB camera on the wearer’s glasses. The videos were pre-processed using EgoBlur to preserve the privacy of the recording participants. Note that there is a third person in the room, the moderator, who may be present in the video recordings, but does not speak.accelerometercontains npy files (<recording-id>.npy) with a matrix of(x,y,z)measurements obtained from the accelerometer with 1000 Hz sampling frequency in numpy formatgyroscopecontains npy files (<recording-id>.npy) with a matrix of(x,y,z)measurements obtained from the gyroscope with 1000 Hz sampling frequency in numpy formattranscriptionscontain one tsv file per recording (<recording-id>.tsv). Each file contains one line per word, in format<start-of-word>\t<end-of-word>\t<word>\t<speaker>.<start–of-word>and<end-of-word>are in seconds and were obtained by forced alignment of the annotated segments<speaker>is 0 or 1, where 0 denotes SELF (the wearer of the glasses), while 1 denotes OTHER (the conversation partner). These are not speaker-identity labels, i.e. 0 in one recording is not the same speaker as 0 in another one. You can find the speaker-identity labels in metadata.
rttmcontain one file per recording (<recording-id>.npy) in the standard rttm format, with one line per segment as:SPEAKER <recording-id> 1 <start-of-segment-in-seconds> <duration-of-segment-in-seconds> <NA> <NA> <0 or 1> <NA> <NA>As in the transcriptions, 0/1 refers to SELF/OTHER. The segments were obtained from human annotations. Note that the segments might often overestimate the actual speaking time, thus use these with caution if you want to evaluate speaker diarization or speaker activity detection performance.metadatacontain one file per recording (<recording-id>.json), which contains a dictionary in json format with following keys:self_speakerid of SELF speakerother_speakerid of OTHER speakernoise_categorytype of noise
During test-time, systems may use only audio, video, accelerometer and gyroscope data. The rest - transcriptions, rttm, and metadata may be used only for analysis or evaluation of performance.
Aria glasses
Detailed information on the Aria glasses can be found at the website of the Aria project, especially in the documentation.
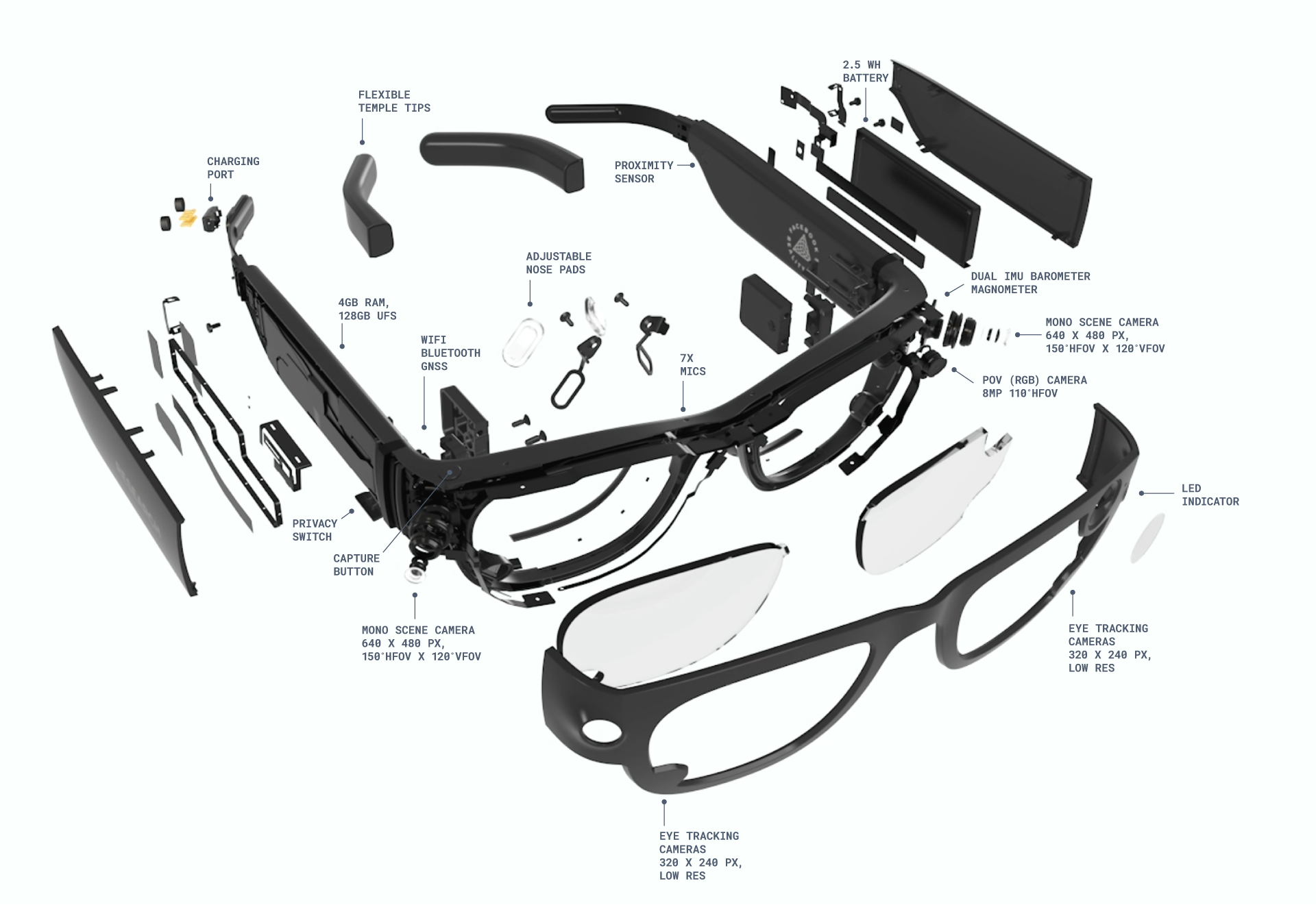
Project Aria glasses have five cameras (two Mono Scene, one RGB, and two Eye Tracking cameras) as well as non-visual sensors (two IMUs, magnetometer, barometer, GPS, Wi-Fi beacon, Bluetooth beacon and microphones).
The specifications of the sensors used for collecting the data can be found in Project Aria Recording Profiles under profile 21. The sensors in Aria glasses used in this challenge are:
- The IMU sensor operating at 1000 Hz located at the right temples of the glasses
- Seven-channel spatial microphone array with a sampling rate of 48kHz
- Videos recorded with the RGB camera
The positions of the microphones at the glasses are specified below. The coordinates are x,y,z where x is going from back to front, y from right to left and z from bottom to up - all from the point of view of the wearer and in centi-meters. The order of the microphones is as in the data.
| position | x [cm] | y [cm] | z [cm] |
|---|---|---|---|
| back → front | right → left | bottom → up | |
| lower-lens right | 9.95 | -4.76 | 0.68 |
| nose bridge | 10.59 | 0.74 | 5.07 |
| lower-lens left | 9.95 | 4.49 | 0.76 |
| front left | 9.28 | 6.41 | 5.12 |
| front right | 9.93 | -5.66 | 5.22 |
| rear right | -0.42 | -8.45 | 3.35 |
| rear left | -0.48 | 7.75 | 3.49 |
Getting the data
For obtaining the data, please refer to the download link at this website. Note that a registration is needed to obtain the data and they should not be further distributed to not-registered individuals.